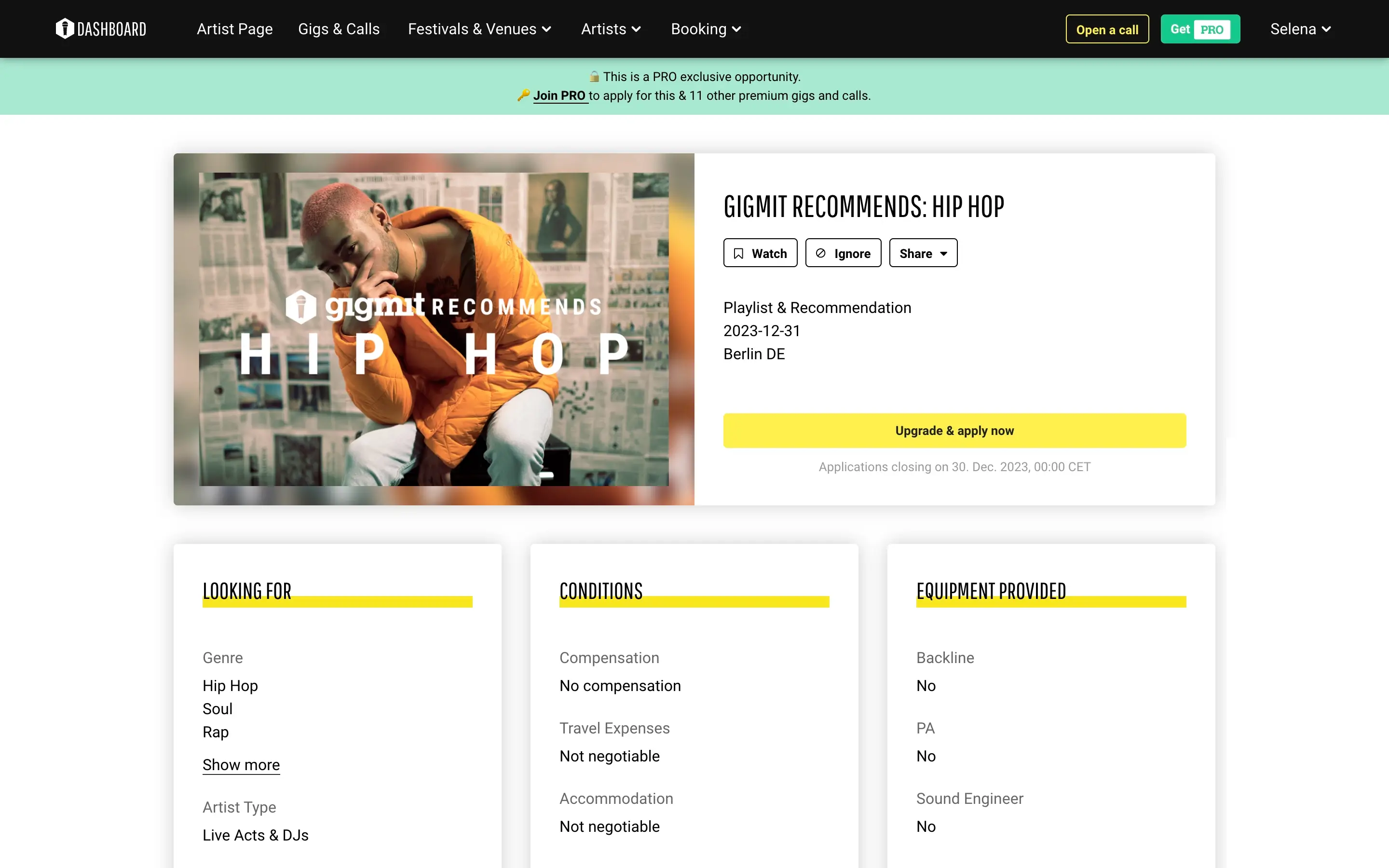
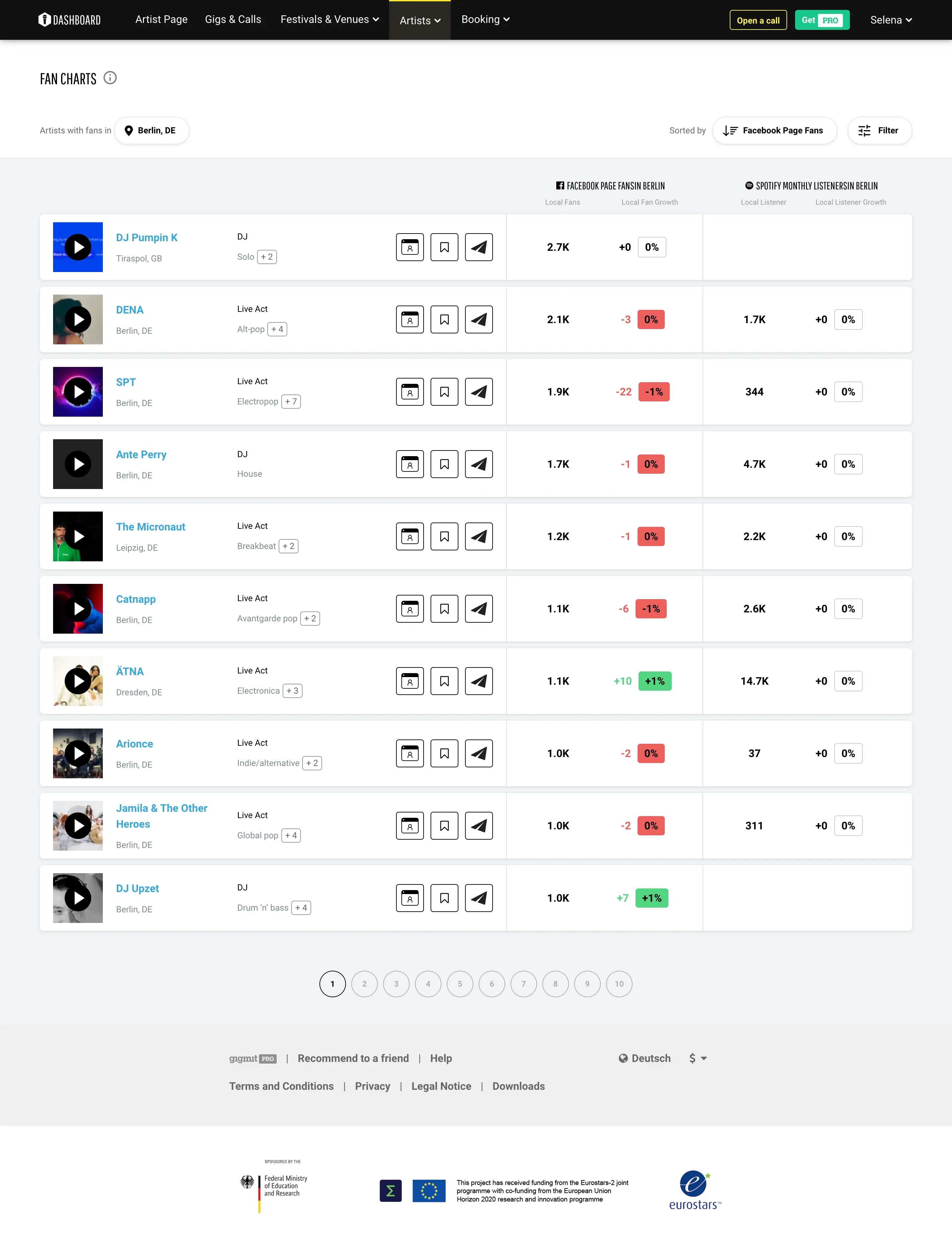
Gigmit
Berlin, Deutschland




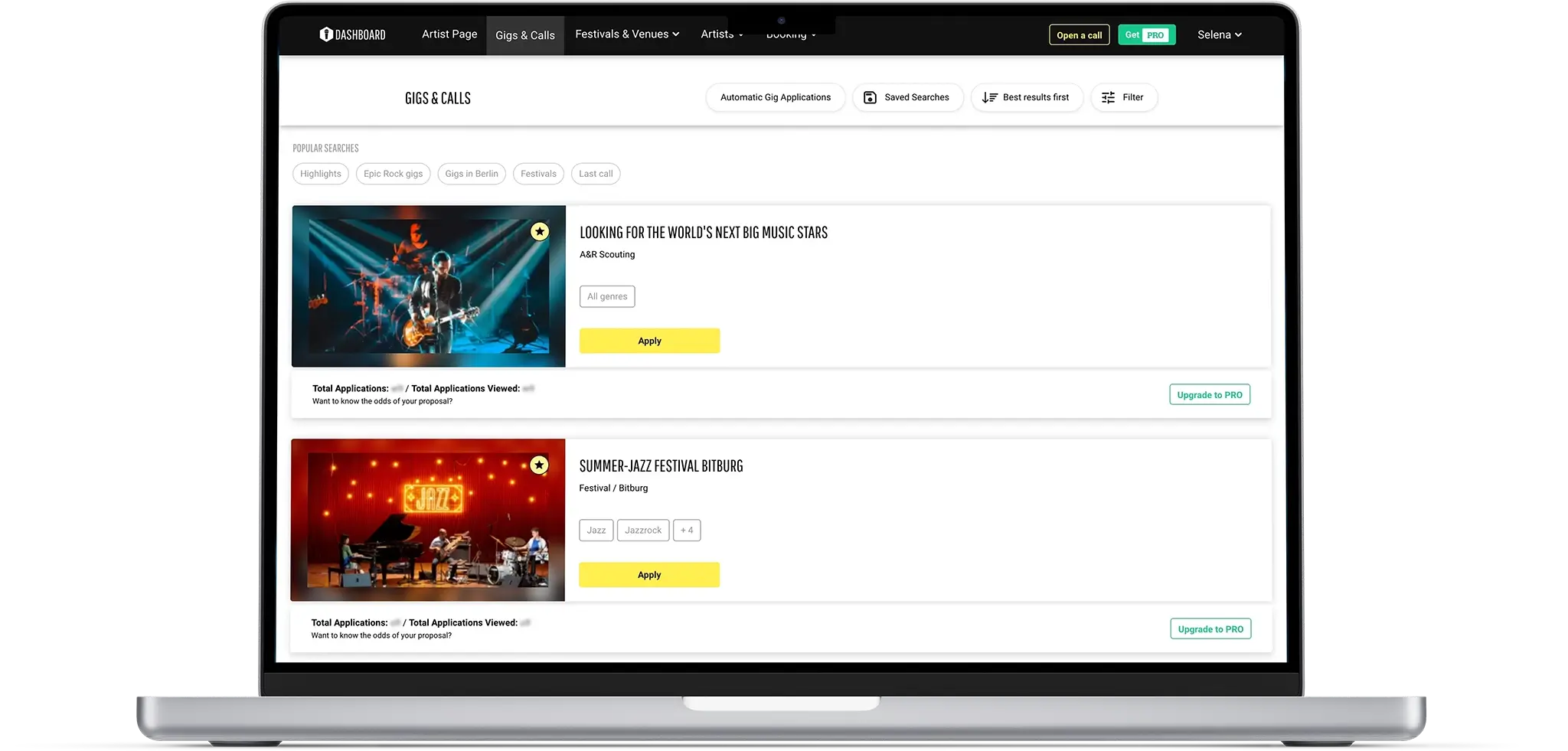
gigmit ist ein Online-Portal für Live-Musikbuchungen, das Künstlern hilft, mehr Auftritte zu buchen und Veranstalter passende Künstler zu finden. Es nutzt datengetriebene Algorithmen, um Künstler perfekt mit Gigs, Festivals und anderen Veranstaltungen zu verbinden, je nach Genre, bevorzugtem Standort und Fanbasis.
Alle KundenData Mining
Wir haben gigmit dabei geholfen, ihre Datenbank mit neuen Festivals, Veranstaltungsorten sowie zugehörigen Kontakt- und Standortinformationen zu erweitern. Dazu nutzten wir eine Kombination aus API-Anfragen und HTML-Parsing, um die Daten abzurufen und zu organisieren, und hielten uns strikt an ihre Datenstrukturanforderungen.
Mehr erfahrenMedien & Unterhaltung
Wir haben gigmit dabei unterstützt, ihre Mission zu verfolgen, das Live-Musikgeschäft für jeden zugänglich zu machen. Indem wir ihnen halfen, ihre Datenbank zu vergrößern und zu bereichern, haben wir ihren Nutzern eine größere Auswahl an Möglichkeiten geboten, was auch zu höherem Vertrauen und Loyalität der Verbraucher führt.
Mehr erfahrenHerausforderung
Die Natur des Geschäfts unseres Kunden erfordert kontinuierliches Datenharvesting, um sicherzustellen, dass die Endnutzer eine ständig wachsende Auswahl an relevanten und aktuellen Optionen haben. Einfach ausgedrückt, stellt gigmit sicher, dass Künstler leicht wünschenswerte Musikfestivals, Messen, Shows oder spezielle Veranstaltungsorte finden und die Organisatoren kontaktieren können.
Um dieses Ziel zu erreichen, sammelt gigmit öffentlich verfügbare Informationen von einer Vielzahl von Musik- und Unterhaltungswebseiten in einer einzigen Datenbank. Vor unserer Partnerschaft sammelte gigmit die notwendigen Daten mit Hilfe von Scrapy, einem Open-Source-Web-Crawler für die Datenextraktion mit APIs und allgemeinem Web-Scraping.
Allerdings stießen sie bei diesem Tool auf bestimmte Einschränkungen, weshalb sie sich an Redwerk wandten, um ihnen beim Daten-Scraping und Parsing einer ausgewählten Anzahl von Webressourcen zu helfen. Natürlich erwartete man von uns, dies auf eine Weise zu tun, die den Betrieb der genannten Ressourcen nicht beeinträchtigt und ohne blockiert zu werden. Außerdem mussten wir unter Zeitdruck arbeiten.
Lösung
Der erste Schritt bestand darin, die bestehende Web-Scraping-Strategie zu bewerten und einen neuen Tech-Stack auszuwählen, der weniger Einschränkungen bei der Datenextraktion und -anzeige mit sich bringt.
Wir wählten Django REST, um Datenmodelle zu erstellen und die Interaktionen mit der Datenbank zu verwalten. Dieses Framework ermöglichte es uns, die gesammelten Daten effizient zu organisieren und zu verwalten.
Wir erstellten asynchrone Aufgabenwarteschlangen mit Celery und RabbitMQ, um zu vermeiden, dass die Server mit API-Anfragen überlastet werden. So stellten wir sicher, dass unsere Anfragen geordnet und kontrolliert verarbeitet werden.
Kontaktinformationen waren nicht immer sofort verfügbar, daher nutzten wir die Leistung von Hunter.io, einem KI-gesteuerten E-Mail-Finder.
Die größte Herausforderung bestand darin, das Gleichgewicht zwischen Parsing-Geschwindigkeit und den Grenzen der Hosting-Server zu finden. Dennoch sammelten wir alle benötigten Daten ethisch korrekt, ohne Serviceunterbrechungen oder Beschwerden von den Webadministratoren.
Ergebnis
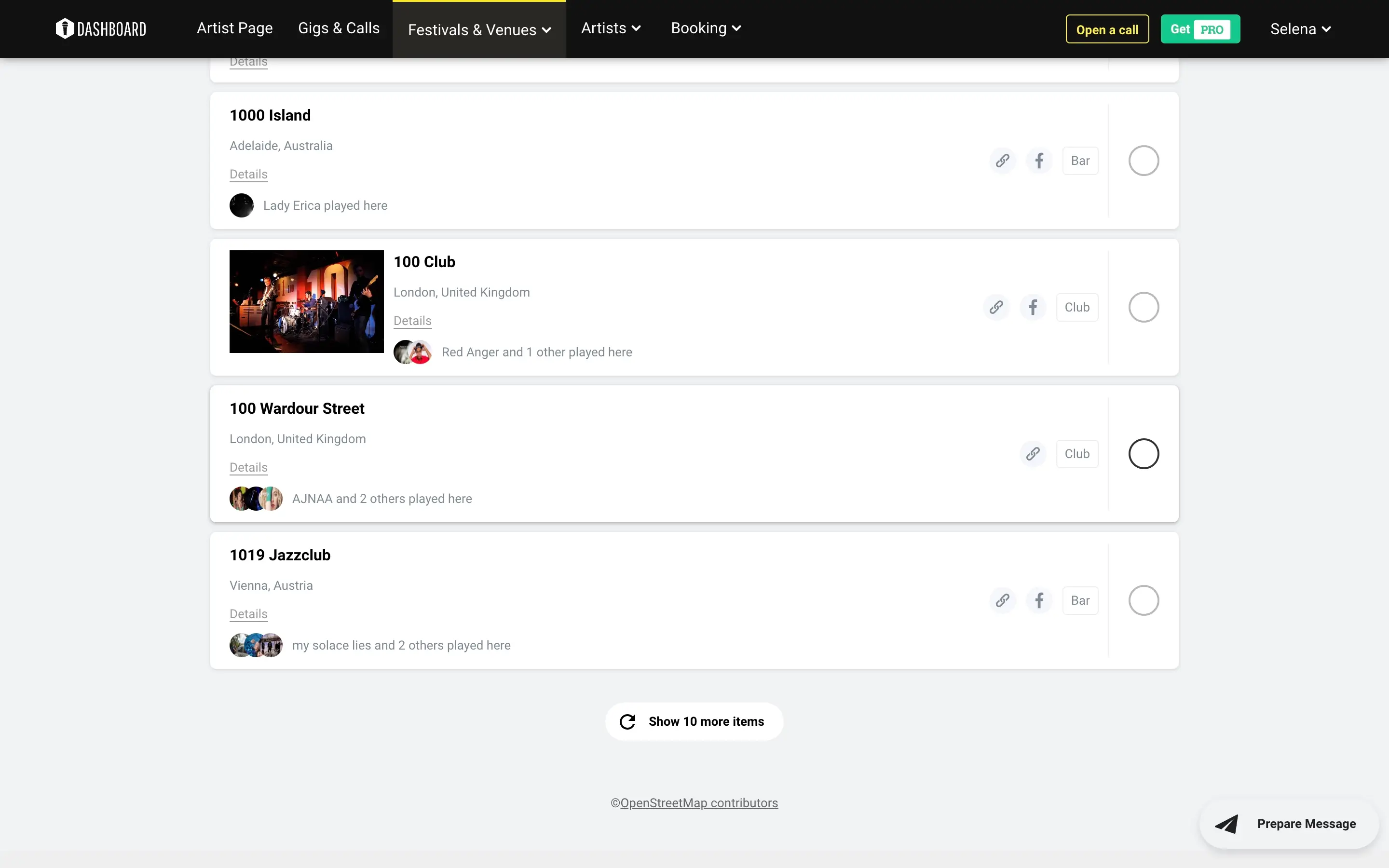
Mit unserer Hilfe hat gigmit seine Datenbank um Musikfestivals, spezielle Veranstaltungsorte, Pubs, Kinos, Kunstzentren und Theater erweitert, zusammen mit den zugehörigen Gigs und Kontaktdaten. Wir lieferten gut strukturierte Daten in SQL-Tabellen und XLSX-Dateien gemäß den Datenstrukturanforderungen. Der Erfolg von gigmit als Unternehmen beruht auf aktuellen und relevanten Daten, und wir haben ihnen geholfen, diese zeitnah zu erhalten, damit ihre Abonnenten all diese Möglichkeiten sehen und sich für passende Gigs bewerben können.
Wir sind stolz darauf, dass gigmit in die USA expandiert, und wir werden sie weiterhin unterstützen und unser technisches Know-how teilen, um ihr stetiges Wachstum in den kommenden Jahren zu gewährleisten.
Wir nutzen Daten und setzen uns dafür ein, dass diese Daten transparent zugänglich gemacht werden. Irgendwann werden wir in der Lage sein, vorherzusagen, wie voll ein Konzert in der Zukunft sein wird.
Von den Plattformen sorgt gigmit für das größte Aufsehen. Gegründet im Jahr 2012 ist die Seite eine Art Tinder für die Musikbranche, die perfekt passende Veranstaltungsorte und Künstler zusammenbringt.
gigmit wurde am 11. November 2012 unter dem Motto ‚Simple booking. Booking simply.‘ gestartet. Zum zehnten Jahrestag hat gigmit 225.000 Nutzer aus über 120 Ländern.

Eine digitale Lösung könnte die Welt der Live-Musik vereinfachen und beiden Seiten helfen - den Veranstaltern einen gefilterten Blick geben und den Künstlern zeigen, wo die Möglichkeiten liegen.

Brauchen Sie ein zuverlässiges Werkzeug für sicheres Datenharvesting?
Sprechen Sie mit ExpertenTechnologien
 Django REST
Django REST Celery
Celery Hunter.io
Hunter.io PostgreSQL
PostgreSQLRedwerk Team Kommentare

Oleksandr
Entwickler
Ich habe eine Mischung aus API-Anfragen und HTML-Seiten-Parsing verwendet, um die erforderlichen Daten zu sammeln. Ich habe bewährte Strategien angewendet, um zu vermeiden, dass die Dienste, von denen die Daten gesammelt wurden, überlastet werden. Dieses Projekt erforderte ein wenig Problemlösung, aber sobald der richtige Tech-Stack ausgewählt war, wurde alles sehr klar und einfach.
Verwandt im Blog

Wie Sie den richtigen Tech-Stack für Ihr Projekt auswählen
Softwareentwicklung ist eine komplexe Angelegenheit. Jedes Projekt besteht hauptsächlich aus dem Konzept und den Menschen, die dieses Konzept zum Leben erwecken. Deadlines, Ressourcen und natürlich Technologien werden meist später definiert. Aber das bedeutet nicht, dass die Wahl...
Beeindruckt?
Beauftragen Sie unsWeitere Fallstudien
Orderstep
Unterstützung bei der Steigerung der Abonnementeinnahmen durch Entwicklung eines Premium-Webshop-Moduls

CDP Blitz
Optimierte Datenbank und erweiterte Funktionalität eines Medienverzeichnisses mit über 35.000 Einträgen
Android Bug Hunter
Entwicklung eines All-in-One-Toolkits für manuelles Testen, das Android-Produktteams stärkt