Sports Events Crawler




Der Kunde ist ein Unternehmen, das professionelle Sport-Softwarelösungen anbietet.
Alle KundenProduktentwicklung
Redwerk hat diese automatisierte Lösung zum Crawling von Sportturnieren von Grund auf entwickelt. Unser professionelles Team hat an jeder Phase des Prozesses gearbeitet: Analyse, Design, Entwicklung, Test, Bereitstellung, Wartung und Support.
Mehr erfahrenDatenbergbau
Wir führen Scraping von Websites und APIs sozialer Netzwerke als Big Data durch, nachdem sie automatisch verarbeitet wurden, um archivierte Websites für die Nutzer wiederherzustellen.
Mehr erfahrenHerausforderung
Das Kundenunternehmen bietet das Know-how, um Sportveranstalter bei der Durchführung von lokalen, regionalen und landesweiten Turnieren zu unterstützen. Obwohl die maßgeschneiderten Softwarelösungen des Unternehmens auf dem neuesten Stand der Technik sind, wurden nicht alle Prozessschritte optimiert. So basierte die Suche und Datenerfassung auf einem rein manuellen Prozess und bedurfte daher einer drastischen Überarbeitung. Die Suche, Speicherung und Verarbeitung der Daten musste manuell erfolgen, was nur bis zum Erreichen einer bestimmten Datenmenge effektiv war. Es war daher notwendig, diesen Workflow zu automatisieren, und hier kamen die flexiblen Software-Experten von Redwerk ins Spiel.
Unsere Aufgabe war es, den ursprünglichen, manuellen Algorithmus des Kunden zu automatisieren, der in etwa wie folgt aufgebaut war:
- Suche nach Schlüsselbegriffen.
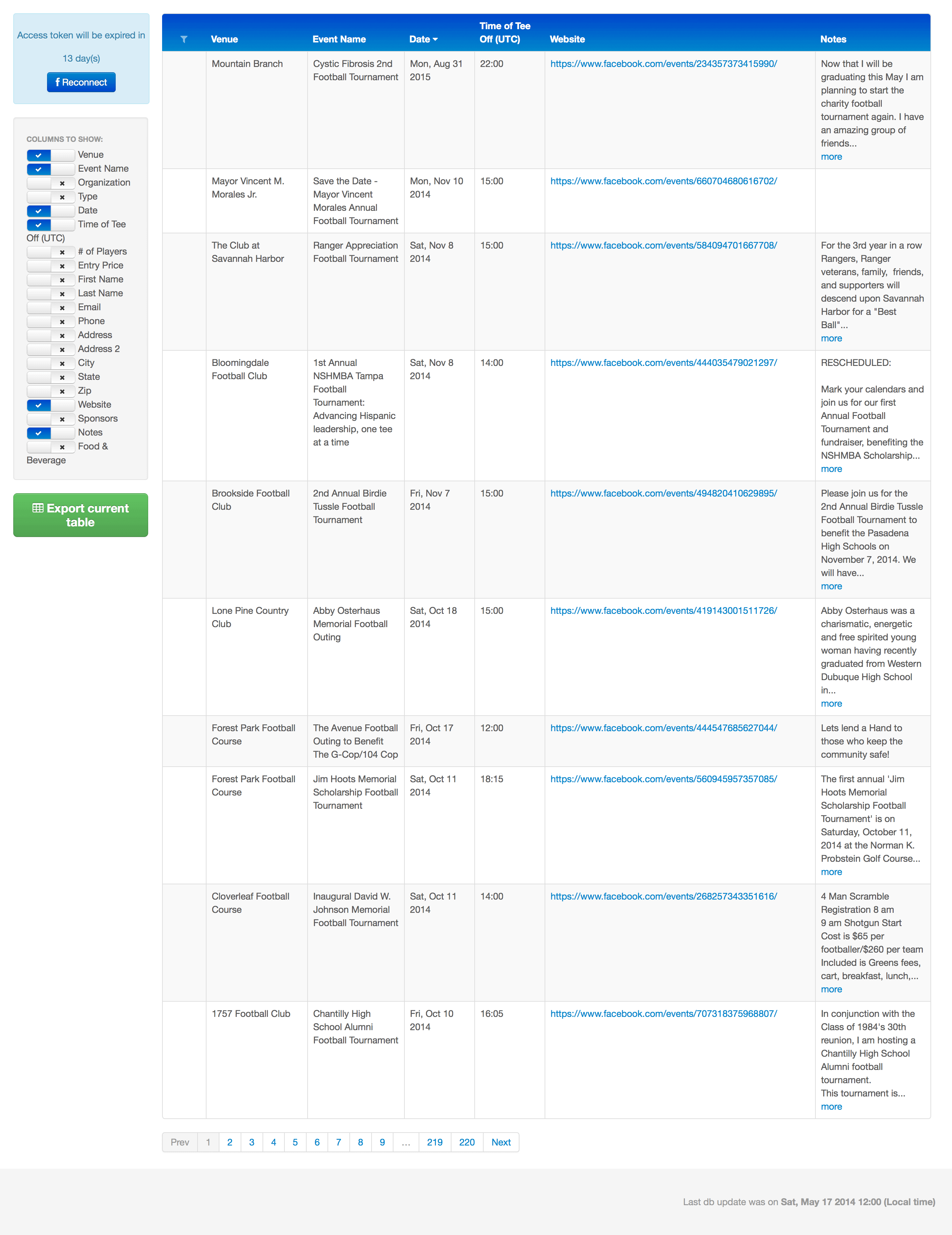
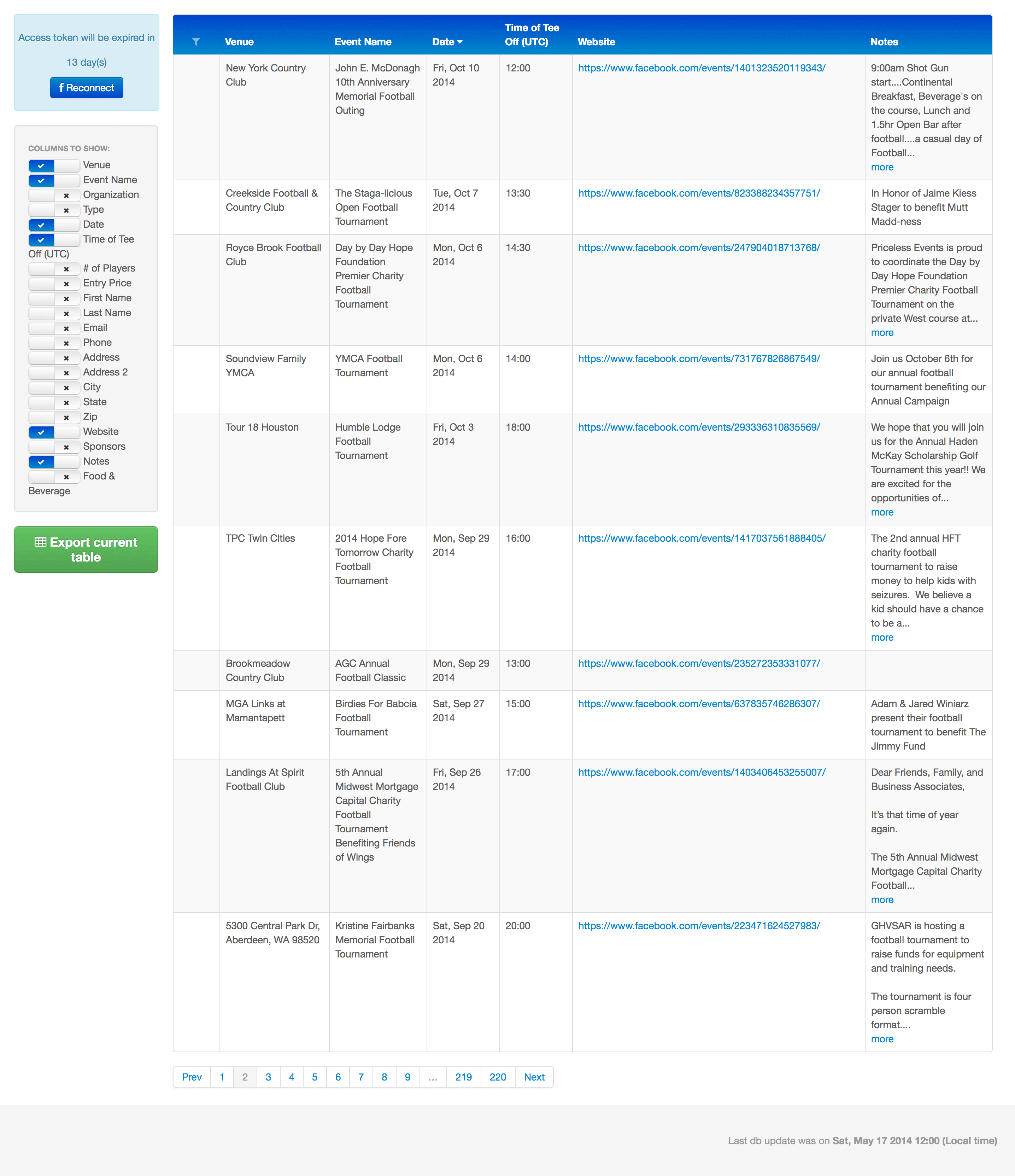
- Zusammenstellung der Suchspezifikationen und -ergebnisse: Suchbegriff, Suchdatum, Seite der Suche, Titel, URL, Typ, Snippet, Cache-Bild, Cache-Details.
- Extrahieren der wichtigsten Informationen aus Snippets, Titeln, URL’s, etc. Zuweisung dieser Informationen zu den entsprechenden Suchergebnissen.
- Erkennen und Sortieren der extrahierten Daten in Kategorien.
Kurz und bündig: Redwerk wurde beauftragt, eine Lösung zu entwickeln, die automatisierte Web-Suche und Web-Crawling kombiniert. Zusätzlich wurden wir gebeten, eine Datenspeicherlösung zu bauen, um Informationen zu sortieren und Abfragen durchzuführen.
Für den Endbenutzer bedeutet dies, dass die Software es nun einfacher macht, Turniere und Veranstaltungen zu finden und alle relevanten Turnierinformationen und Kontaktdaten zu erhalten.
Unsere Recherche
Redwerk stand vor einer schwierigen Aufgabe, da alle Informationen automatisch gefunden, analysiert und strukturiert werden mussten. Dies machte es schwierig, deterministische Ansätze für das schnelle Auffinden von Informationen anzuwenden. Die erforderlichen Analysemethoden wären sehr aufwendig zu implementieren gewesen, und es zeigte sich bald, dass deterministische Algorithmen nicht geeignet waren, Seiten mit zufälligen Strukturen zu verarbeiten.
Erst wenn man den Ausgangspunkt modifiziert, indem man davon ausgeht, dass es eine endliche Anzahl von Quellen gibt, aus denen Informationen gezogen werden müssen, wird ein solcher Ansatz wegen der relativen Einfachheit und Bestimmtheit gerechtfertigt. Trotz der Tatsache, dass das Data-Mining von Zufallsinformationen eine sehr interessante Aufgabe ist und einige Vorteile bringen kann, schien es für diese spezielle technische Lösung nicht geeignet. Wenn die Anwendung nicht in der Lage wäre, eine bestimmte Menge an Daten mit hoher Genauigkeit zu finden, wäre sie nicht von Nutzen.
Das Team von Redwerk evaluierte verschiedene Ansätze für diese Software-Herausforderung.
Data-Mining
Diese Methode wäre eine direkte Automatisierung des bestehenden Arbeitsablaufs des Kunden gewesen. Um Daten zu extrahieren, erforderte diese Methode die Analyse, das Verständnis und die Verknüpfung von Teilen der natürlichen Sprache. Während Menschen Substantive, Verben, Namen, Adressen usw. auf einer Webseite sehen, sehen Maschinen nur Zeichenketten und Zahlen. Die Entwicklung eines selbstlernenden Systems, das natürliche Sprache sorgfältig verstehen kann, ist eine der schwierigsten Aufgaben in der IT.
Auch wenn wir für diese spezielle Lösung ein viel einfacheres System in Erwägung zogen, dem schrittweise „beigebracht“ würde, über eine einfache Schnittstelle Daten von verschiedenen Arten von Websites zu erfassen, schien dieser Ansatz für unseren Kunden einfach nicht zu funktionieren.
Vorteile:
- Die fortschrittlichste und zukunftsweisendste Lösung, große Datenmengen, die im Laufe der Zeit gesammelt werden
Nachteile:
- Zeitaufwendige Implementierung
- Komplexe Algorithmen
- Ressourcenintensiv
- Die teuerste Lösung
Soziale Netzwerke
Soziale Netzwerke erfreuen sich großer Beliebtheit und haben ein riesiges Publikum, weshalb sie bei Werbetreibenden, die auf bestimmte Ereignisse aufmerksam machen wollen, immer beliebter werden. Als beliebtestes soziales Netzwerk der Welt wurde Facebook als Untersuchungsgegenstand gewählt. Wir untersuchten, inwieweit diese Art von Veranstaltung in sozialen Netzwerken beworben wurde, welche Menge an nützlichen Daten abgerufen werden konnte und wie fragmentiert/zuverlässig diese Daten sein würden.
Die Ergebnisse unserer Facebook-Studie waren überwiegend positiv. Viele Sportturniere werden auf Facebook gepostet, und es werden ständig neue Veranstaltungen hinzugefügt. Dank der API von Facebook ist es einfach, Daten aus dem sozialen Netzwerk zu sammeln und zu verarbeiten.
Vorteile:
- Schnell wachsende Datenbank mit Ereignissen
- Einfache Datenerfassung und -verarbeitung über API
- Einfachste und schnellste Lösung zur Implementierung
Nachteile:
- Keine Kategorisierung der Ereignisse
- Nicht besonders sportartspezifisch
- Falsch eingegebene Informationen (z. B. Angabe der Stadt als Veranstaltungsort)
Datenaggregation
Eine weitere Möglichkeit, Informationen über bevorstehende Sportereignisse zu sammeln, ist der Abruf von Informationen von spezialisierten Sport-Websites. Diese sind so konzipiert, dass sie Informationen über themenbezogene Ereignisse in einer praktischen Form bereitstellen, was die von diesen Websites gewonnenen Daten für die Zwecke unseres Kunden sehr wertvoll macht. Einige verfügen über Abonnementsysteme und bieten APIs für einen einfachen Datenzugriff, was eine schnelle Implementierung der Datenerfassung und -verarbeitung ermöglicht.
Unsere Forschung konzentrierte sich jedoch auf ein Szenario, in dem keine kommerziellen Datenquellen verwendet werden und so viele Daten wie möglich „kostenlos“ gesammelt werden müssen. Unter dieser Prämisse hätten wir Webcrawler entwickeln müssen, um Daten aus dem Quellcode von HTML-Seiten herunterzuladen, zu analysieren und zu extrahieren.
Vorteile:
- Größte Menge an genauen und relevanten Daten
Nachteile:
- Individueller Ansatz für jede Website erforderlich
- Die Datenextraktion wird oft von Webmastern erschwert
- Kosten und Entwicklungszeiten steigen mit der Anzahl der Websites, es sei denn, es werden APIs verwendet
Unsere Lösung
In Anbetracht der verschiedenen Vor- und Nachteile der oben genannten Ansätze wurde beschlossen, nicht einen von ihnen zu verwenden, sondern eine Kombination der letzten beiden Ansätze, nämlich Facebook-Datenanalyse und Datenaggregation. Die Verwendung bestehender Aggregatoren als primäre Datenquelle für Informationen über bevorstehende Ereignisse schien die vorteilhafteste Methode in Bezug auf die Menge der abgerufenen wertvollen Daten zu sein, wenn man sorgfältig vorgeht. Zusätzliche Informationen werden von unserer maßgeschneiderten Lösung auch von Facebook abgerufen.
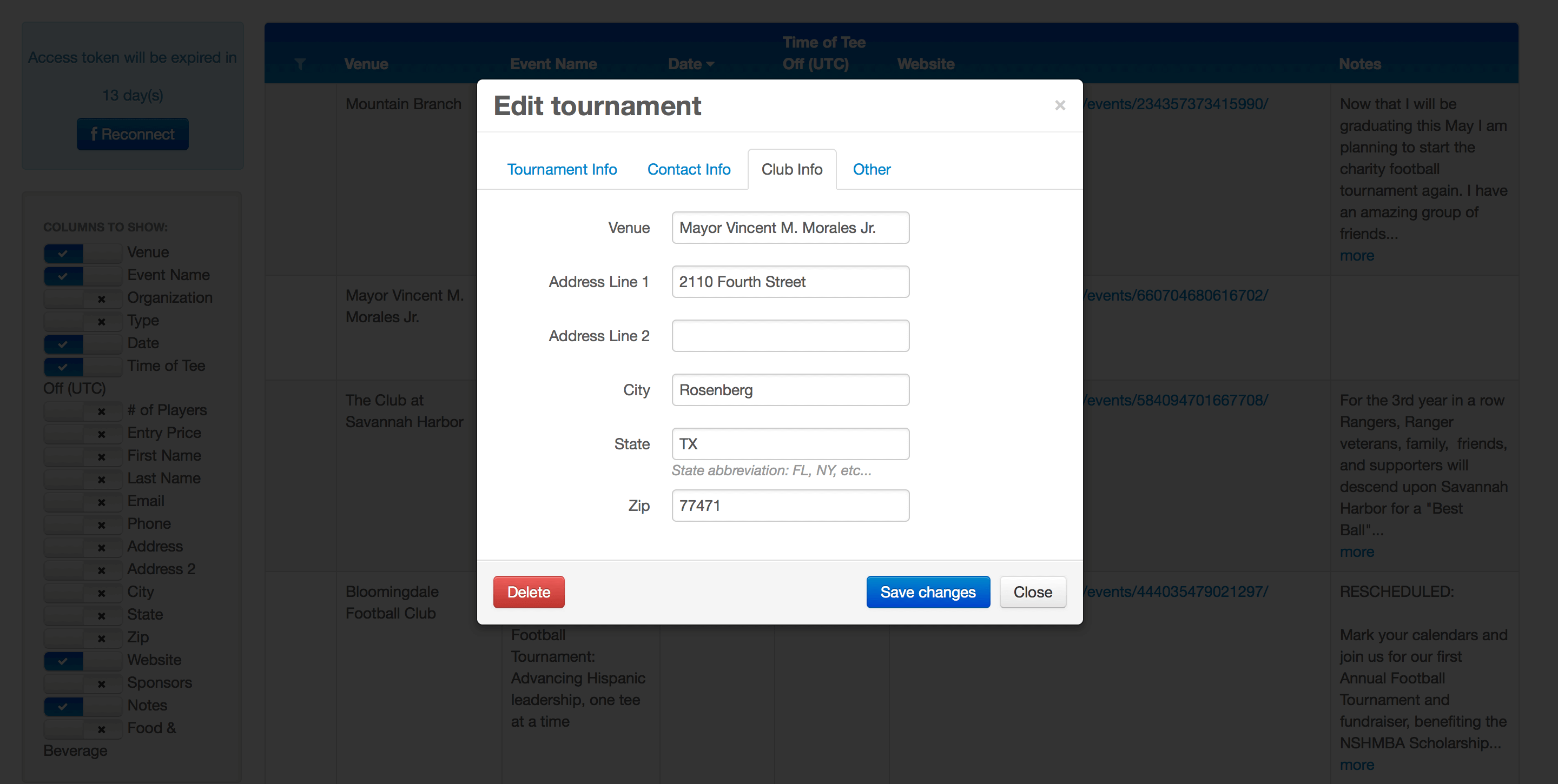
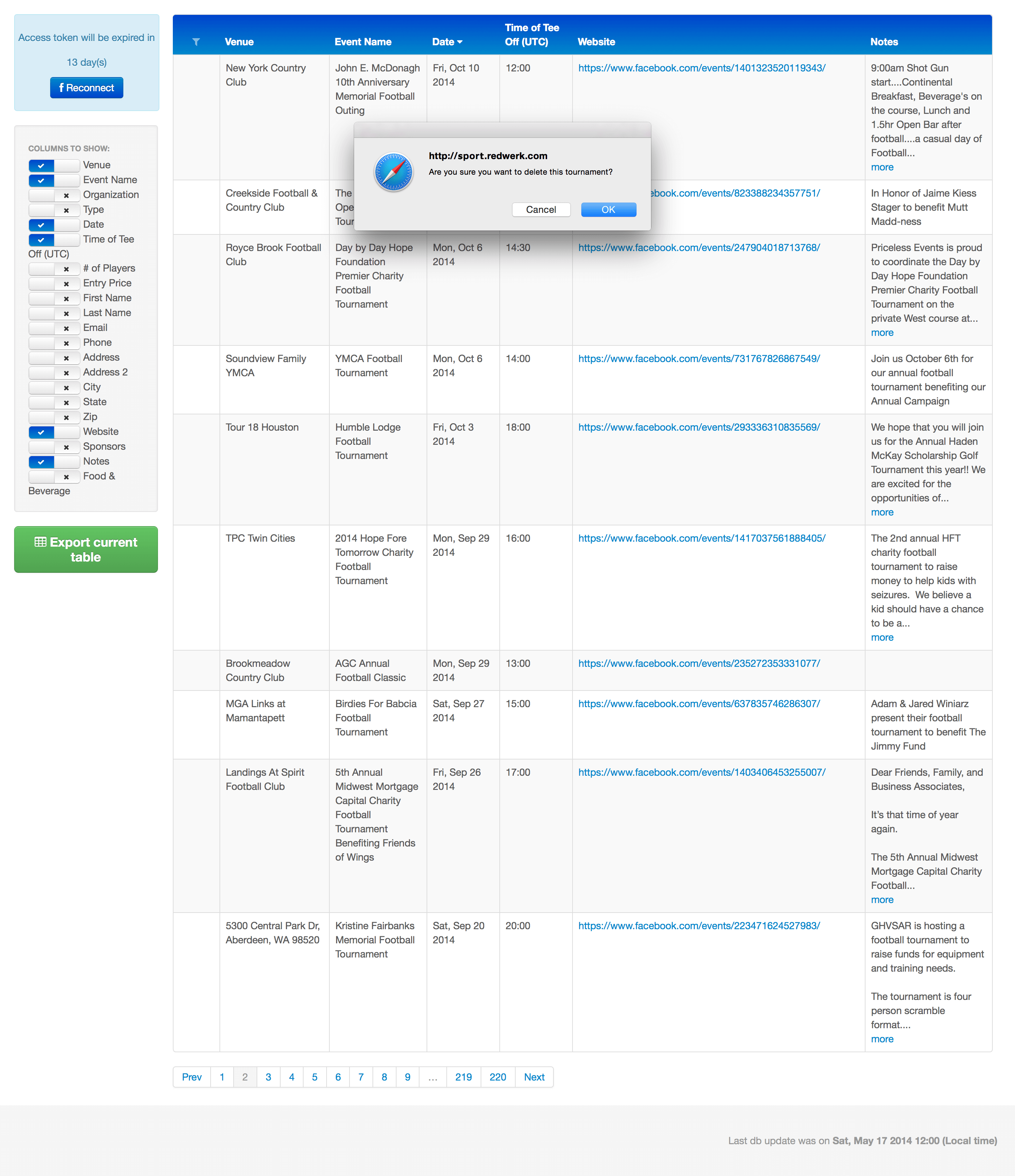
Dank der automatisierten Web-Crawling-Prozesse, die von den Redwerk-Ingenieuren implementiert wurden, ermöglicht diese Lösung das Filtern und Suchen von Sportereignissen nach einer Reihe von verschiedenen Kriterien. Sie zeigt Links zu den entsprechenden Seiten an, von denen die Informationen stammen (Facebook-Veranstaltungsseiten), sowie andere Arten von Informationen und ermöglicht die einfache Bearbeitung und/oder Löschung bestimmter Veranstaltungen.
Ergebnis
Das Team von Redwerk erkannte schnell, dass es sehr schwierig, kostspielig und zeitaufwändig ist, den manuellen Algorithmus unseres Kunden mit automatisierten Prozessen lediglich zu replizieren. Stattdessen konzentrierten wir uns auf die Implementierung einer Suchstruktur mit einer festen Anzahl von Datenquellen, von denen Facebook im Prototyp verwendet wurde. Diese Art von System war viel einfacher zu implementieren und zu warten und erfüllte die ursprünglichen Anforderungen perfekt.
Mit dieser Lösung gelang es Redwerk, seinem Kunden wertvolle Zeit und Geld zu sparen, und unsere Ingenieure fanden eine elegante Lösung für ein kniffliges Problem, von der in Zukunft viele professionelle Sportveranstalter profitieren dürften.
Müssen Sie sich um Web-Crawling kümmern?
Lassen Sie uns redenTechnologien
Verwandt im Blog

Scala vs Java 8: 10 Important Differences
Viele Java-Entwickler lieben Scala und bevorzugen es gegenüber Java, sei es für neue Projekte, Komponenten bestehender Java-Projekte oder sogar für leistungskritische Teile vorhandener Java-Module. Dank dessen hat Scala seinen Weg in die Unternehmenswelt gefunden und gewinnt T...
Beeindruckt?
Stellen Sie uns einAndere Fallstudien
Animatron
Erweiterte Funktionalität eines Startups für Animationssoftware, anerkannt von Geschäftsmedien wie Entrepreneur, MonsterPost und Freelancer

Linktiger
Ein Prüfprogramm für defekte Links, das mehr als 3 Millionen Links durchsuchen kann und von großen Namen wie Hosting.com, Microsoft und dem US-Verkehrsministerium verwendet wird
PageFreezer
Entwickelte eine Website- und Social-Media-Marketing-SaaS, die in die engere Wahl für die Red Herring Top 100 Global Finalist kam