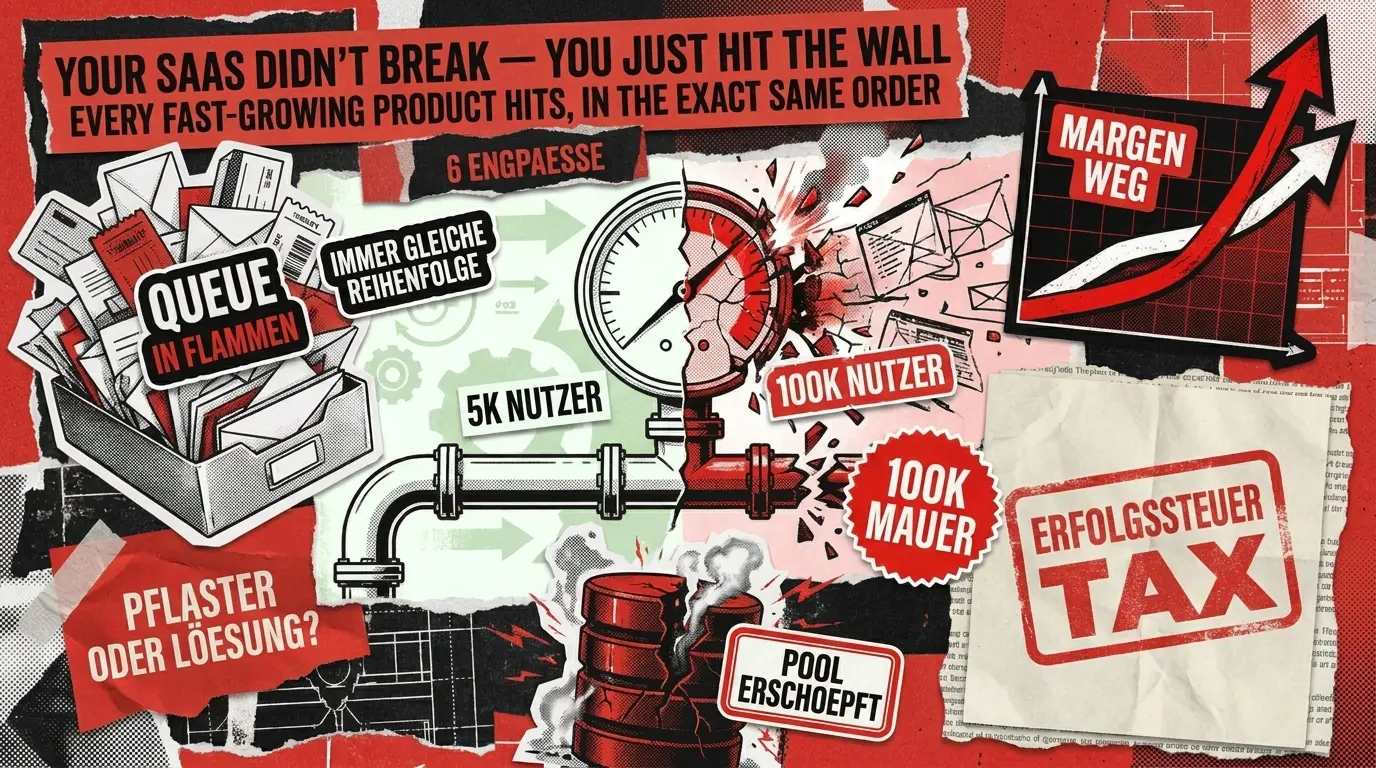
Niemand warnt Sie vor dem genauen Moment, in dem Ihr SaaS-Erfolg sich wie eine Bestrafung anfühlt, denn die Notwendigkeit, ein SaaS-Geschäft zu skalieren, trifft Sie oft aus dem Nichts. Meistens passiert es über Nacht: Das Produkt, das bei 5.000 Nutzern reibungslos lief, beginnt bei 30.000 zu wackeln, und bei 80.000 befindet es sich offiziell im künstlichen Koma. Plötzlich ist Ihr Support-Posteingang ein loderndes Chaos, Ihre Entwickler haben die Roadmap aufgegeben und sind zu Vollzeit-Feuerwehrleuten geworden, und Ihre Infrastrukturrechnung wächst weit schneller als Ihr Bankkonto.
Wenn Ihnen das schmerzlich vertraut klingt, atmen Sie tief durch. Sie haben kein schlechtes Produkt gebaut, und Ihr Team hat das Programmieren nicht vergessen. Sie zahlen gerade einfach die ‘Erfolgssteuer’.
Die tröstliche Wahrheit ist, dass dieses Chaos nicht zufällig ist. Nach zwei Jahrzehnten des Aufbaus und der Skalierung von SaaS-Entwicklung-Projekten haben wir ein eindeutiges Muster bemerkt: Engpässe lieben einen Zeitplan. Sie treten in einer höchst vorhersehbaren Reihenfolge auf, ausgelöst durch ganz bestimmte Nutzerzahl-Meilensteine.
Wenn Ihr Team genau weiß, was um die Ecke kommt, können Sie die Leitungen reparieren, bevor Ihre Kunden jemals ein Leck bemerken. Das ist das Geheimrezept, das die SaaS-Giganten, die mühelos skalieren, von denen trennt, die in technischen Schulden und Nutzerabwanderung versinken.
Bei Redwerk haben wir über 250 Softwareprojekte abgeliefert. Das bedeutet, wir haben diesen Skalierungs-Horrorfilm oft genug erlebt, um genau zu wissen, wann das Monster herausspringt.
Betrachten Sie diesen Artikel als Ihre ultimative Überlebenskarte. Wir schlüsseln alle sechs vorhersehbaren Engpässe auf, die genauen Meilensteine, bei denen sie auftreten, die frühen Warnsignale, auf die Sie achten sollten, und – am wichtigsten – den Unterschied zwischen einem schnellen, vorübergehenden Pflaster und einer dauerhaften Lösung. Tauchen wir ein.
Ein SaaS-Unternehmen skalieren: Schnellreferenz für die Engpass-Diagnose
Die nachfolgende Tabelle fasst alle sechs in diesem Artikel behandelten Engpässe zusammen. Verwenden Sie sie als Referenzkarte, wenn Sie versuchen, das, was Sie in der Produktion sehen, seiner wahrscheinlichen Ursache zuzuordnen.
Erschöpfung des Datenbank-Verbindungspools
~20K
Zufällige Timeouts bei Aktionen, die gestern noch schnell waren
Aktive Verbindungen vs. Pool-Maximum; Abfrage-Wartezeiten; ‘zu viele Verbindungen’-Fehler
Pool-Größe erhöhen, Lese-Replikas hinzufügen
Verbindungs-Pooler (PgBouncer); separate Lese-/Schreibpfade
Sättigung der Hintergrundaufgaben-Warteschlange
~40K
E-Mails kommen 20 Minuten zu spät an; Exporte hängen
Warteschlangen-Tiefentrend; Auftragsalter bei der Verarbeitung; Worker-Wartezeit vs. Laufzeit
Mehr Worker hinzufügen
Prioritätswarteschlangen-Lanes; Ingestion-Ratenbegrenzung
Cache-Invalidierungs-Chaos
~60K
Veraltete Daten nach dem Speichern; inkonsistente Dashboards
Cache-Trefferrate; TTL-Audit; mandantenübergreifende Schlüsselkollisionsprüfung
TTLs global reduzieren
Tag-basierte oder ereignisgesteuerte Invalidierung pro Mandant
Noisy-Neighbor-Degradierung
~80K
Bestimmte große Konten verlangsamen sich unvorhersehbar
Abfragezeit pro Mandant; gemeinsame Ressourcennutzung nach Mandanten-ID
Den lautesten Mandanten manuell ratenbegrenzen
Mandanten-Tier-Ressourcenpartitionierung; dedizierte Compute-Pools
Kosten-pro-Nutzer-Inversion
~100K
Noch nichts sichtbar, aber die Margen schrumpfen
Kosten-pro-aktiven-Nutzer-Trend; Leerlauf-Ressourcenverhältnis; Ausgaben vs. Umsatz pro Kohorte
Reservierte Instanzen, Spot-Compute, Rightsizing
Kostenzuordnung nach Mandant; Feature-Flag für aufwändige Workloads
Organisations- und Prozess-Skalierungsversagen
~150K
Features verlangsamen sich; Vorfälle dauern länger zur Behebung
MTTD/MTTR-Trends; Deployment-Häufigkeit; reaktives vs. proaktives Engineering-Verhältnis
Mehr Prozess- und Koordinationsmeetings
Eigentumsverantwortung auf Dienste ausgerichtet; Runbooks; Observability-Investitionen
Was "Ein SaaS-Unternehmen skalieren" in jeder Phase wirklich bedeutet
Die meisten Teams gehen in ein Skalierungsgespräch und denken an Performance: Dinge schneller machen, mehr Anfragen verarbeiten. Diese Sichtweise ist nicht falsch, aber unvollständig. Skalieren bedeutet wirklich, zu identifizieren, was als Nächstes brechen wird, und es zu beheben, bevor die Nutzer es tun.
Jede Wachstumsphase führt eine dominante Einschränkung ein. Der Instinkt, Rechenressourcen auf ein Problem zu werfen oder die gesamte Architektur auf einmal neu zu schreiben, ist genau deshalb teuer, weil er diesen Punkt übersieht. Der richtige Schritt ist fast immer gezielter: Finden Sie die spezifische Einschränkung in Ihrer aktuellen Phase, beheben Sie sie ordentlich und instrumentieren Sie für die nächste, die kommt.
Die sechs folgenden Abschnitte gehen jede Einschränkung in der Reihenfolge durch, in der sie typischerweise auftritt.
1. Warum SaaS bei 20K Nutzern langsamer wird: Erschöpfung des Datenbank-Verbindungspools
Aktionen, die monatelang schnell waren, fangen intermittierend an, ein Timeout zu erzeugen. Die Ausfälle häufen sich während der Geschäftszeiten, wenn die gleichzeitige Nutzung am höchsten ist, und verschwinden dann am Abend. Nutzer öffnen Tickets, Ihr Team prüft die Datenbank und findet sie weit innerhalb der Kapazität. Was passiert also?
Warum dies beim SaaS-Skalieren passiert
Ihre Anwendung unterhält einen Pool offener Datenbankverbindungen, die Anfragen ausleihen und zurückgeben können. Bei niedrigen Nutzerzahlen ist dieser Pool groß genug im Verhältnis zur gleichzeitigen Nachfrage. Wenn Ihre monatlich aktiven Nutzer (MAU) in Richtung 20.000 klettern, überschreitet die Anzahl gleichzeitiger Anfragen schließlich den Pool. Neue Anfragen reihen sich in die Warteschlange ein und warten darauf, dass eine Verbindung verfügbar wird. Wenn die Wartezeit das Anfrage-Timeout überschreitet, sieht der Nutzer einen Fehler. Unterdessen sieht die Datenbank selbst gut aus, weil der Engpass in der Verbindungsverwaltungsschicht liegt, nicht in der Datenbankengine.
Dieses Szenario ist häufiger als die meisten Teams erwarten. Wie ein Entwicklerteam nach dem Profiling seines eigenen Systems feststellte, kann die Erschöpfung des Verbindungspools P99-Latenz-Spitzen verursachen, selbst wenn die Datenbank selbst bei 47% Auslastung liegt. Was wie ein Datenbankkapazitätsproblem aussieht, ist tatsächlich Stau in der Verbindungswarteschlange.
3 Anzeichen, auf die Sie in Ihrem System achten sollten
- Anzahl aktiver Verbindungen vs. Ihr konfiguriertes Pool-Maximum (erreichen Sie regelmäßig die Obergrenze?)
- Abfrage-Wartezeit in der Prozessaktivitätsansicht Ihrer Datenbank (pg_stat_activity in PostgreSQL oder das Äquivalent in Ihrer Engine)
- Fehlerprotokolle für ‘zu viele Verbindungen’, ‘Pool erschöpft’ oder ähnliche Meldungen, abgeglichen mit Zeitstempeln von Nutzerbeschwerden
Schnelle Linderung vs. dauerhafte Lösung
Die Notlösung besteht darin, Ihre Pool-Größe zu erhöhen und Lese-Replikas hinzuzufügen, um Zeit zu gewinnen. Die architektonische Lösung ist die Einführung eines dedizierten Verbindungs-Poolers, wie PgBouncer im Transaktionsmodus, der viele Anwendungsverbindungen in weit weniger Datenbankverbindungen multiplext. Gleichzeitig sollten Sie Ihren Lesepfad (Dashboard-Abfragen, Berichterstattung) von Ihrem Schreibpfad entkoppeln, damit sie nicht um denselben Pool konkurrieren.
2. Ein häufiges SaaS-Skalierungsproblem bei 40K Nutzern: Sättigung der Hintergrundaufgaben-Warteschlange
E-Mail-Bestätigungen, die in Sekunden ankommen sollten, dauern jetzt 20 Minuten. Dateiexporte, die früher sofort bereit waren, zeigen lange einen Ladekreisel und schlagen dann stillschweigend fehl. Webhooks an die Systeme Ihrer Kunden hören auf zu liefern. Keiner dieser Fehler erscheint als Fehler auf Ihrem Haupt-Dashboard, was diesen Engpass besonders heimtückisch macht.
Warum dies beim SaaS-Skalieren passiert
Mit wachsender Nutzerzahl wächst auch das Arbeitsvolumen, das Ihr Hintergrundaufgaben-System verarbeiten muss, oft schneller als die Nutzerzahl selbst, weil viele Nutzeraktionen mehrere Hintergrundaufgaben auslösen. Schließlich sammeln sich Aufträge schneller an, als Ihre Worker sie abarbeiten können. Neue Aufträge warten hinter einem Rückstand. Zeitkritische Aufgaben wie E-Mails stehen hinter aufwändigen Batch-Exporten in der Schlange. Worker erscheinen beschäftigt, aber der Großteil ihrer Echtzeit wird mit Warten verbracht, nicht mit Ausführen.
Das ist besonders gefährlich, weil die Fehler still sind. Enterprise-Kunden bemerken es vor Ihnen, weil ihre Webhook-Integrationen anfangen, Ereignisse zu verpassen. Bis die Support-Tickets eintreffen, ist das Vertrauen bereits beschädigt.
3 Anzeichen, auf die Sie in Ihrem System achten sollten
- Warteschlangen-Tiefentrend der letzten 24 Stunden (wächst er im Laufe des Tages, anstatt konstant zu bleiben?)
- Auftragsalter zum Zeitpunkt der Verarbeitung (warten Aufträge 15 Minuten, bevor sie überhaupt beginnen?)
- Worker-CPU- vs. Echtzeit-Verhältnis (Worker, die den Großteil ihrer Zeit mit Warten verbringen statt mit Ausführen, signalisieren einen Durchsatz-Engpass, keinen Kapazitätsengpass)
Schnelle Linderung vs. dauerhafte Lösung
Die schnelle Lösung ist das Hinzufügen weiterer Worker. Das hilft vorübergehend, verursacht aber oft ein neues Problem: Aufwändige Batch-Jobs konkurrieren mit zeitkritischen nutzerseitigen Jobs, und die Warteschlange füllt sich innerhalb von Wochen wieder. Die architektonische Lösung sind priorisierte Warteschlangen-Lanes mit separaten dedizierten Warteschlangen für nutzerseitige Aufgaben (E-Mails, In-App-Benachrichtigungen, Webhook-Lieferung) und interne Batch-Arbeit (Exporte, Analytics-Aggregation, Suchindizierung). Ergänzen Sie dies durch Ratenbegrenzung auf der Ingestion-Seite, damit ein plötzlicher Anstieg neuer Ereignisse Ihre Prioritätswarteschlange nicht begraben kann.
3. Veraltete Daten und defekte Dashboards: Cache-Invalidierungsprobleme bei 60K Nutzern
Ein Nutzer speichert eine Änderung, und die Seite zeigt noch die alten Daten. Zwei Personen auf demselben Konto sehen unterschiedliche Zahlen im selben Dashboard. Ein gelöschter Datensatz taucht immer wieder auf, und Ihr Support-Team beginnt, diese als Bugs zu protokollieren. Als Ihr Entwicklerteam nachforscht, sind die zugrunde liegenden Daten in der Datenbank korrekt; der Cache liefert einfach eine veraltete Version.
Warum dies beim SaaS-Skalieren passiert
Caching ist eines der effektivsten Werkzeuge zur Reduzierung der Datenbanklast, wenn ein SaaS-Produkt skaliert. Cache-Invalidierung – die Entscheidung, wann ein zwischengespeicherter Wert nicht mehr gültig ist und ersetzt werden sollte – ist jedoch tatsächlich eines der schwierigeren Probleme in verteilten Systemen. Bei 60.000 MAU werden die Fehlermodi, die in kleinerem Maßstab handhabbar waren, sichtbar. In Multi-Tenant-Umgebungen ist ein häufiges Problem die Cache-Schlüsselkollision: Die Daten zweier Mandanten werden auf überlappende Weise als Schlüssel verwendet, sodass der Schreibvorgang eines Mandanten versehentlich veraltete Daten an einen anderen liefert. Ein weiteres Problem ist die übermäßige Abhängigkeit vom Time-to-Live (TTL)-Ablauf, was bedeutet, dass veraltete Daten so lange bestehen bleiben, wie die TTL es ist, selbst wenn sich der zugrunde liegende Datensatz Sekunden nach dem Schreiben des Caches ändert.
3 Anzeichen, auf die Sie in Ihrem System achten sollten
- Cache-Trefferrate aufgeschlüsselt nach Endpunkt (ein plötzlicher Rückgang der Trefferrate geht oft sichtbaren Veralterungsbeschwerden voraus)
- TTL-Verteilungsaudit über Ihre zwischengespeicherten Objekte (verwenden stark frequentierte Objekte TTLs, die länger sind als die Toleranz Ihrer Nutzer für veraltete Daten?)
- Mandantenübergreifende Cache-Schlüsselkollisionsprüfung in Ihrer Multi-Tenant-Umgebung (sind Ihre Schlüssel eng genug auf den Mandanten und die Ressourcenversion beschränkt?)
Schnelle Linderung vs. dauerhafte Lösung
Als erstes sollten Sie die TTLs überall reduzieren. Das verkleinert das Zeitfenster für veraltete Daten, erhöht aber die Datenbanklast erheblich, was oft andere Probleme auslöst. Die architektonische Lösung ist der Wechsel zu tag-basierter oder ereignisgesteuerter Invalidierung, bei der ein Schreibvorgang auf eine Ressource explizit alle zwischengespeicherten Ansichten dieser Ressource invalidiert, geordnet nach Mandanten-ID und Ressourcenversion. Wechseln Sie außerdem zu Write-Through-Caching auf Ihren meistgenutzten Lesepfaden, sodass Cache und Datenbank bei jedem Schreibvorgang gemeinsam aktualisiert werden. Weitere Hinweise zur Strukturierung der Mandantenisolierung in Ihrer Cache-Schicht finden Sie in unserem Leitfaden zu Best Practices für Multi-Tenant-SaaS-Architektur.
4. Noisy-Neighbor-Degradierung: Eine Multi-Tenant-SaaS-Skalierungsherausforderung bei 80K Nutzern
Ihre größten, wertvollsten Konten beginnen, sich über Verlangsamungen zu beschweren. Das Timing ist inkonsistent und korreliert mit nichts Offensichtlichem auf ihrer Seite. Was wie ihr Problem aussieht, wird tatsächlich durch ein anderes Konto verursacht, das gleichzeitig gemeinsam genutzte Infrastruktur verbraucht.
Warum dies beim SaaS-Skalieren passiert
In einer Multi-Tenant-Architektur teilen mehrere Kunden dieselbe Datenbank, Anwendungsserver und Cache-Infrastruktur. Ein einzelner großer Mandant, dessen Nutzung legitim hoch ist – ein komplexer Export, die Verarbeitung eines Massen-Imports oder das Ausführen von Analytics-Abfragen – kann einen unverhältnismäßig großen Anteil gemeinsamer Ressourcen verbrauchen. Andere Mandanten auf derselben Infrastruktur erhalten dadurch eine schlechtere Leistung. Das ist das Noisy-Neighbor-Problem, und es wird typischerweise rund um 80.000 MAU sichtbar, weil dann die Verteilung der Mandantengrößen breit genug ist, dass die schwersten Mandanten wirklich mit allen anderen konkurrieren.
3 Anzeichen, auf die Sie in Ihrem System achten sollten
- Abfragezeitperzentile pro Mandant (korrelieren Ihre langsamsten P95-Perioden mit einer oder zwei spezifischen Mandanten-IDs, die mehr Ressourcen verbrauchen als andere?)
- Gemeinsame Ressourcenauslastung aufgeschlüsselt nach Mandanten-ID (Speicher-IOPS, Verbindungsanzahl, CPU)
- Verbindungsanzahl pro Mandant während der Beschwerdezeiträume
Schnelle Linderung vs. dauerhafte Lösung
Die Notlösung besteht darin, den lautesten Mandanten manuell zu ratenbegrenzen, wenn eine Beschwerde eingeht. Das ist reaktiv, da es Ihre Beziehung zu diesem Mandanten beschädigt und nicht verhindert, dass dasselbe Szenario nächste Woche mit einem anderen Mandanten wiederkehrt. Die architektonische Lösung ist mandanten-tier-basierte Ressourcenpartitionierung: Konten mit hoher Nutzung erhalten dedizierte Compute-Pools oder Datenbankschemata mit eigenen Ressourcenzuweisungen, während kleinere Konten einen gemeinsamen Pool teilen, der entsprechend ihrer aggregierten Nutzungsmuster dimensioniert ist. Dies eröffnet auch einen natürlichen Weg zu gestaffelten Preisen, bei denen Enterprise-Kunden für dedizierte Infrastruktur zahlen.
5. Wenn die Skalierung eines SaaS-Unternehmens teuer wird: Kosten-pro-Nutzer-Inversion bei 100K Nutzern
Dieser Engpass ist für Ihre Kunden unsichtbar, was ihn teilweise so gefährlich macht.
Was Ihr Team bemerkt
Die Infrastrukturrechnung ist in den letzten sechs Monaten um das Dreifache gewachsen. Ihre Nutzerzahl ist im gleichen Zeitraum um etwa 50% gestiegen. Die Mathematik, die in Ihrem Unit-Economics-Modell überzeugend aussah, funktioniert nicht mehr. Laut Flexera’s 2025 State of the Cloud Report identifizieren 84% der Organisationen das Management von Cloud-Ausgaben als ihre größte Cloud-Herausforderung, wobei Cloud-Budgets Prognosen bereits durchschnittlich um 17% überschreiten. SaaS-Produkte stoßen akut rund um 100.000 MAU an diese Wand, weil dort architektonische Ineffizienzen, die in kleinerem Maßstab tolerierbar waren, zu echter Margeneinbuße zu kumulieren beginnen.
Umsätze in SaaS wachsen pro Sitz oder pro Plan. Infrastrukturkosten wachsen pro Interaktion: jeder API-Aufruf (Application Programming Interface), jede Datenbankabfrage, jedes gespeicherte oder übertragene Gigabyte. Wenn diese Kurven aufhören proportional zu sein, haben Sie eine Kosten-pro-Nutzer-Inversion, und wenn Sie die zugrunde liegende Architektur nicht beheben, verschlechtert sich die Inversion mit dem Wachstum.
3 Anzeichen, auf die Sie in Ihrem System achten sollten
- Kosten-pro-aktiven-Nutzer-Trend der letzten 90 Tage (nicht Gesamtausgaben, sondern Ausgaben geteilt durch MAU, wöchentlich verfolgt)
- Leerlauf-Ressourcenverhältnis (welcher Prozentsatz Ihres bereitgestellten Computings ist während der Nebenzeiten inaktiv?)
- Compute-Ausgaben vs. Umsatz aufgeschlüsselt nach Kundenkohorte (sind bestimmte Plan-Tiers oder Feature-Sets bei aktuellen Infrastrukturkosten tatsächlich unrentabel?)
Schnelle Linderung vs. dauerhafte Lösung
Sie können versuchen, Instanzen zu dimensionieren, für unkritische Workloads zu Spot-Compute zu wechseln und reservierte Kapazitäten zu erwerben. Diese Maßnahmen sind sinnvoll und sollten umgesetzt werden, aber sie sind Optimierungen, keine Architektur. Die Behebung des Problems auf Architekturebene erfordert eine Kostenzuordnung nach Mandant, damit Sie genau wissen, was jeder Kunde tatsächlich kostet, und Feature-Flagging für aufwändige Workloads, sodass ressourcenintensive Features nur für Tiers aktiv sind, deren Preisgestaltung die Kosten unterstützt. Darüber hinaus deckt eine Überprüfung Ihrer Datenaufbewahrungs- und Log-Speicherrichtlinien in dieser Phase fast immer erhebliche Verschwendung auf: Daten, für deren Speicherung Sie zahlen, die aber niemand abfragt.
6. Die verborgene SaaS-Skalierungsherausforderung bei 150K Nutzern: Organisations- und Prozessversagen
Feature-Releases verlangsamen sich spürbar. Wenn etwas kaputt geht, dauert die Behebung länger als früher. Das Kunden-Onboarding, das früher eine Woche dauerte, dauert jetzt drei. Ihr NPS (Net Promoter Score) beginnt zu sinken, obwohl das Produkt selbst nicht schlechter geworden ist.
Was Ihr Team bemerkt
Ein Produktions-Deployment erfordert nun die Koordination von vier oder mehr Personen. Niemand hat ein klares Bild davon, wie alle Dienste interagieren. Wenn ein Vorfall auftritt, wird die Hälfte der Zeit damit verbracht herauszufinden, zu wessen Bereich er gehört. Support-Tickets referenzieren Verhaltensweisen, die das Entwicklerteam in einer Staging-Umgebung nicht reproduzieren kann. Das Verhältnis von reaktiver Arbeit (Beheben bereits kaputter Dinge) zu proaktiver Arbeit (Aufbauen noch nicht kaputter Dinge) hat sich still umgekehrt.
Warum dies beim SaaS-Skalieren passiert
Das ist der Engpass, den die meisten Artikel zum Thema SaaS-Skalierung überspringen, weil er sich organisatorisch und nicht technisch anfühlt. Aber er ist genauso vorhersehbar und genauso schädlich wie die fünf vor ihm. Rund um 150.000 MAU sind die Anzahl der Personen in Ihrem Team und die Anzahl der Dienste, für die sie verantwortlich sind, auf einen Punkt gewachsen, an dem informelle Koordination nicht mehr funktioniert. Der kognitive Aufwand für das Aufrechterhalten von gemeinsamem Kontext wird zu hoch, sodass Entscheidungen langsamer werden. Ein Software-Entwicklungsaudit in dieser Phase zeigt oft, dass die technischen Symptome, Deployment-Fehler, nicht reproduzierbare Bugs und Überwachungslücken nachgelagerte Folgen struktureller Probleme in der Organisation von Ownership und Observability sind.
3 Anzeichen, auf die Sie in Ihrem System achten sollten
- Mittlere Erkennungszeit (MTTD) und mittlere Behebungszeit (MTTR)-Trends für Vorfälle der letzten sechs Monate (beide sollten mit der Reife eines Produkts sinken; wenn sie steigen, ist das ein strukturelles Signal)
- Deployment-Häufigkeit pro Team oder Dienst (werden Deployments seltener und formeller?)
- Verhältnis von reaktiver zu proaktiver Engineering-Arbeit im letzten Quartal (wenn das Team mehr als 40% seiner Zeit mit reaktiver Arbeit verbringt, hat die Organisation ein strukturelles Problem, nicht nur ein Rückstandsproblem)
Schnelle Linderung vs. dauerhafte Lösung
Die Notlösung besteht darin, mehr Prozesse hinzuzufügen: mehr Meetings, mehr Genehmigungsschritte, mehr Dokumentationsanforderungen. Diese fühlen sich wie Lösungen an, weil sie das Chaos vorübergehend reduzieren, aber sie verlangsamen auch alles andere. Die ordentliche Lösung auf Architekturebene richtet Ownership-Grenzen explizit auf Dienste aus, sodass jede Komponente des Systems ein benanntes Team hat, das dafür verantwortlich ist. Das bedeutet Bereitschaftsrotationen mit schriftlichen Runbooks, nicht nur informelles Wissen. Das bedeutet die Investition in eine Observability-Plattform, damit das Team sehen kann, was und warum es kaputt gegangen ist, anstatt es durch Raten reproduzieren zu müssen.
Wie Sie erkennen, welcher SaaS-Skalierungsherausforderung Sie gerade gegenüberstehen
Die obige Reihenfolge ist nicht taggenau, aber in ihrer Abfolge zuverlässig. Wenn Ihr Produkt also rund 20.000 bis 40.000 MAU hat und Sie intermittierende Timeouts sehen, beginnen Sie mit Abschnitt 1. Wenn Sie rund 60.000 bis 80.000 MAU haben und Ihre Support-Warteschlange sich mit ‘die Daten sahen falsch aus’-Beschwerden füllt, beginnen Sie mit Abschnitt 3. Wenn Sie über 100.000 MAU haben und Ihre Unit Economics sich still abgeschwächt haben, ist die Kosten-pro-Nutzer-Inversion in Abschnitt 5 der wahrscheinlichste Schuldige.
Die wichtigste Disziplin besteht darin, die Drei-Anzeichen-Prüfungen für den Abschnitt durchzuführen, der Ihrer aktuellen Phase entspricht, bevor Sie annehmen, die Antwort zu kennen. Die Symptome in jeder Phase können von außen täuschend ähnlich aussehen, und die Lösungen sind unterschiedlich genug, sodass eine Verwechslung teuer ist. Eine gut konzipierte, skalierbare Softwarearchitektur ist eine, bei der die Instrumentierung für den nächsten Engpass bereits vorhanden ist, bevor der Engpass entsteht.
Wann Sie externe Hilfe für Ihre SaaS-Produkt-Skalierungsherausforderungen hinzuziehen sollten
Der Zeitpunkt, an dem die meisten Teams externe Hilfe suchen, ist typischerweise einen Engpass zu spät. Es gibt drei zuverlässige Signale, dass Selbstdiagnose nicht mehr der richtige Ansatz ist.
- Erstens deckt Ihr Monitoring nicht die Signale ab, die für Ihre aktuelle Phase relevant sind. Sie können nicht reparieren, was Sie nicht messen können, und wenn die drei oben genannten Anzeichen keine Daten zurückgeben, ist die Observability-Lücke das Erste, was angegangen werden muss.
- Zweitens kämpft Ihr Team wiederholt gegen Feuer im gleichen Bereich. Wenn dieselbe Kategorie von Vorfällen in den letzten drei Monaten drei oder mehr Mal aufgetreten ist, wurde jedes Mal eine Notlösung angewendet statt der architektonischen Lösung.
- Drittens sind die vor 12 bis 18 Monaten getroffenen Architekturentscheidungen nun die Einschränkung. Die meisten SaaS-Produkte sind für die Nutzerzahl ausgelegt, die sie heute haben, nicht die, die sie in 18 Monaten erwarten. Wenn das Wachstum sich beschleunigt, kann die Lücke zwischen der aktuellen und der erforderlichen Architektur zu groß sein, um sie als Team zu schließen und gleichzeitig das Produkt aufrechtzuerhalten.
Wenn eines davon Ihre Situation beschreibt, ist es an der Zeit, ein strukturiertes Gespräch darüber zu führen, was sich ändern muss und in welcher Reihenfolge, also rufen Sie uns an.
FAQ
Wie skaliert man eine SaaS-Anwendung?
Beim Skalieren einer SaaS-Geschäftsanwendung geht es weniger darum, sie ‘schneller zu machen’, als vielmehr darum, zu identifizieren, welche spezifische Einschränkung bei Ihrer aktuellen Nutzerzahl zum Engpass wird, sie ordentlich zu beheben und sich für die nächste zu instrumentieren. Jede Phase ist im obigen Artikel aufgeführt und hat eine eigene Reihe von Symptomen, eine Bestätigungsmethode und eine architektonische Lösung, die sich von der vorübergehenden Notlösung unterscheidet. Teams, die sauber skalieren, sind diejenigen, die jeden Engpass an seiner architektonischen Wurzel angehen, nicht nur an seinem Oberflächensymptom.
Was sind häufige SaaS-Skalierungsprobleme?
Die häufigsten SaaS-Skalierungsprobleme, grob in der Reihenfolge ihres Auftretens mit wachsender Nutzerzahl, sind:
- Datenbank-Verbindungserschöpfung (bei der der Anwendung unter gleichzeitiger Last die verfügbaren Datenbankverbindungen ausgehen)
- Sättigung der Hintergrundaufgaben-Warteschlange (bei der asynchrone Aufgaben wie E-Mails und Webhooks schneller anfallen, als Worker sie verarbeiten können)
- Cache-Invalidierungsfehler (bei denen Nutzern nach Aktualisierungen veraltete Daten geliefert werden)
- Noisy-Neighbor-Degradierung (bei der die Nutzung eines großen Mandanten die Leistung für andere Mandanten auf gemeinsamer Infrastruktur beeinträchtigt)
- Kosten-pro-Nutzer-Inversion (bei der Infrastrukturkosten mit zunehmender Nutzung schneller wachsen als der Umsatz)
- Organisatorisches Prozessversagen (bei dem der Koordinationsaufwand das Engineering verlangsamt, wenn Team- und Systemkomplexität wachsen)
Warum wird meine SaaS langsamer, wenn die Nutzerzahl wächst?
SaaS-Anwendungen werden langsamer, wenn die Nutzerzahl wächst, weil die Architektur, die bei niedrigen Nutzerzahlen gut funktioniert, spezifische Kapazitätsgrenzen hat, die mit steigender Gleichzeitigkeit bindend werden. Die häufigste frühe Ursache ist die Erschöpfung des Datenbank-Verbindungspools: Die Anwendung kann nicht schnell genug neue Datenbankverbindungen öffnen, um alle gleichzeitigen Nutzer zu bedienen, sodass Anfragen sich in der Warteschlange anstauen und ein Timeout erzeugen. Mit wachsender Nutzerzahl füllen sich Hintergrundaufgaben-Warteschlangen, Caching-Schichten liefern veraltete Daten, und gemeinsam genutzte Infrastruktur beginnt Konflikte zwischen Mandanten zu zeigen. Jeder dieser Fehler hat einen vorhersehbaren Auslösepunkt, was bedeutet, dass sie diagnosizierbar und vermeidbar sind, wenn die richtige Instrumentierung vorhanden ist, bevor die Nutzerzahl den Schwellenwert erreicht.
Erfahren Sie, wie wir Recruit Media beim Aufbau eines Recruitment-SaaS geholfen haben, das von einem Nasdaq-notierten Unternehmen mit einer Marktkapitalisierung von über 250 Mio. übernommen wurde



