
Im ersten Teil dieses Artikels wurde ein Beispiel für die Erstellung eines Modells vorgestellt, und wir wurden mit den wichtigsten Schritten der ML vertraut gemacht: Datenvorbereitung, Auswahl der Merkmale, Modelltraining (Auswahl der Modellparameter) und abschließende Bewertung der Ergebnisse (AUC, Precision, Recall usw.).
Lassen Sie uns nun ein reales Beispiel für die Verwendung von Studio zur Lösung eines praktischen ML-Problems betrachten. Dieses Projekt wurde erfolgreich implementiert und wird bereits für die Vorhersage auf der Grundlage von Lebenslauf/Opportunity-Text verwendet.
Das erste, was wir für das maschinelle Lernen benötigen, sind Daten. Alle für das Training benötigten Daten werden in Azure Document DB (Cosmos DB) gespeichert. Um den Prozess der Datenaufbereitung und des zukünftigen Trainings zu verbessern, erhalten wir Daten und speichern sie als Datensatz in Azure ML Studio.
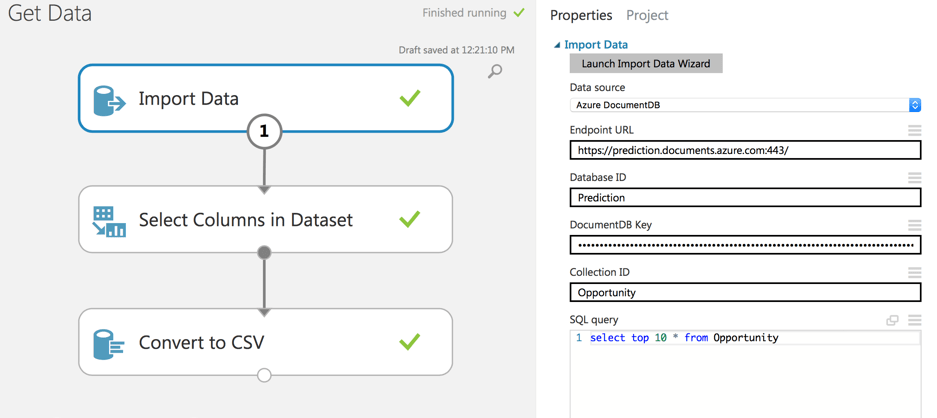
Sobald der Import abgeschlossen ist, können wir ihn visualisieren.
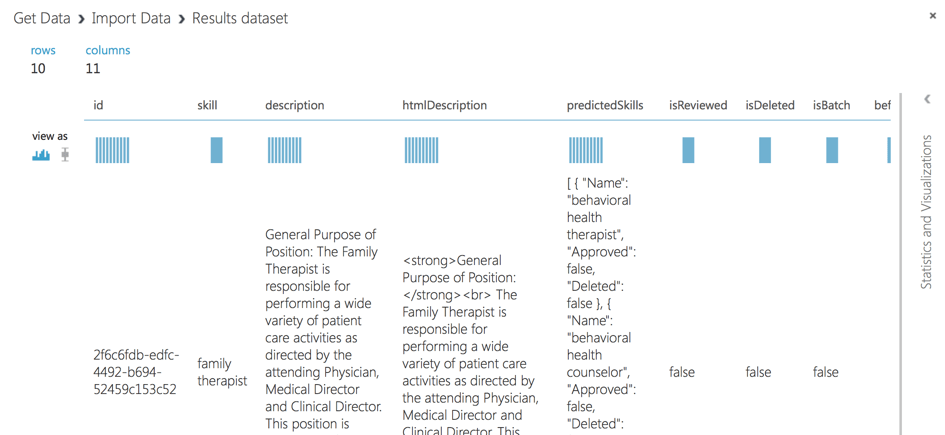
Da die Dokumenten-DB zusätzliche Felder enthält, sollten wir außerdem bestimmte Felder wie Fähigkeiten, Beschreibung usw. auswählen.
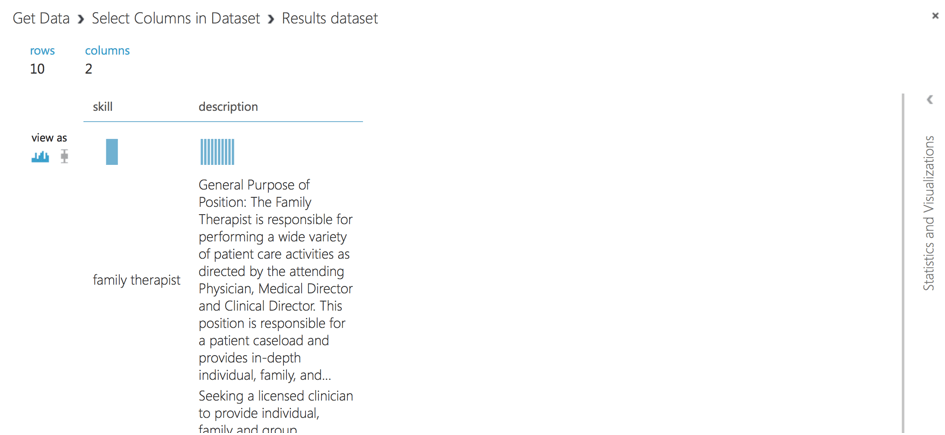
In einem letzten Schritt speichern wir den Datensatz als .csv im Azure ML Studio-Speicher.
Ein Datensatz erfordert normalerweise eine gewisse Vorverarbeitung, bevor er analysiert werden kann. Zum Beispiel könnten wir festgestellt haben, dass in den Spalten verschiedener Zeilen fehlende Werte vorhanden sind. Diese fehlenden Werte müssen bereinigt werden, damit das Modell die Daten korrekt analysieren kann. In diesem Fall werden wir alle Zeilen mit fehlenden Werten entfernen. Dann bereinigen wir den Text mit dem Modul Preprocess Text. Die Bereinigung reduziert das Rauschen im Datensatz, hilft Ihnen, die wichtigsten Merkmale zu finden, und verbessert die Genauigkeit des endgültigen Modells. Wir entfernen Stoppwörter – gängige Wörter wie „der“ oder „a“, Zahlen, Sonderzeichen, doppelte Zeichen, E-Mail-Adressen und URLs. Außerdem wandeln wir den Text in Kleinbuchstaben um, lemmatisieren die Wörter und erkennen Satzgrenzen, die im vorverarbeiteten Text durch das Symbol „“|||“ gekennzeichnet sind.
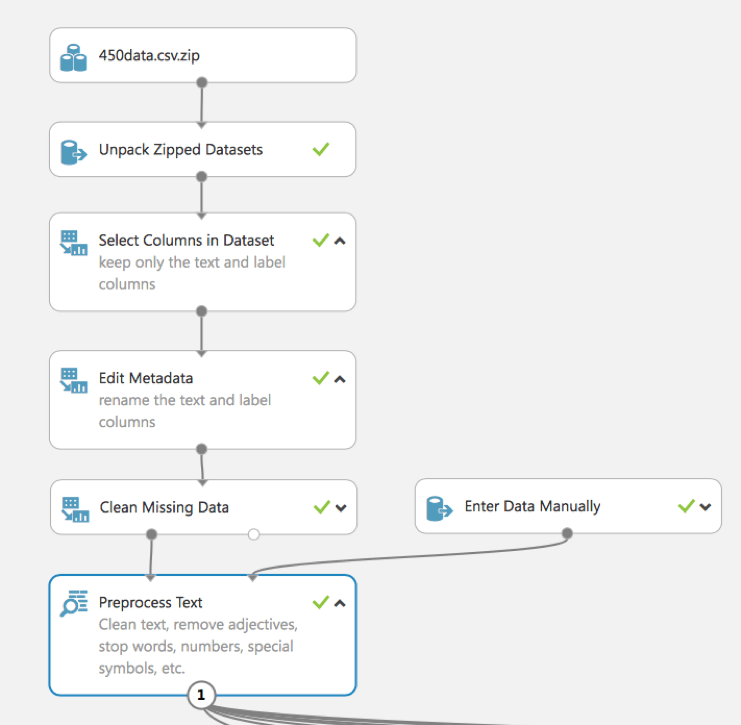
Wie wir sehen, wird in diesem Experiment (im Gegensatz zum Beispiel in Teil 1) das eingebaute Modul Preprocess Text (zuvor haben wir die Verwendung eines R-Skripts gezeigt) verwendet. Es erlaubt uns, den Text zu bereinigen, um Stoppwörter, Zahlen, Sonderzeichen usw. zu entfernen.
Das Hauptziel dieses Schrittes ist es, einen bereinigten Text (Opportunity-Beschreibung) ohne Stoppwörter, Zahlen, E-Mails, URLs usw. zu erhalten. Hier ist zum Beispiel eine Beschreibung vor der Vorverarbeitung:
General Purpose of Position: The Family Therapist is responsible for performing a wide variety of patient care
activities as directed by the attending Physician, Medical Director andClinical Director. This position is
responsible for a patient caseload and provides in-depth individual, family, and group counseling. Counseling
includes the ongoing completion of psychosocial and bio-psychosocial assessments. The Family Therapist collaborates
with the Clinical Team to develop individualized treatment plans and assists in coordinating discharge planning.
This position follows patients' progress from a psychological standpoint, beginning with admittance through
discharge. During this time, the Family Therapist maintains frequent and open communication with the Clinical
Director and Therapists regarding any issues or problems. Primary Responsibilities (include but are not limited to):
Establish individualized family therapy programs, through face to face and/or phone communication with families of
Sunspire Health patients. Conduct and evaluate family assessments...
Und danach:
purpose ||| therapist perform variety care activity as direct physician | director director ||| caseload | depth |
family | group counsel ||| counsel include completion bio | assessment ||| family therapist collaborate develop
treatment plan assist discharge plan ||| follow patient | progress standpoint | begin admittance discharge ||| |
therapist maintain communication director therapist issue problem ||| | include but limit | ||| | establish therapy
program | face face | or communication family sunspire health patient ||| | conduct evaluate assessment ||| |
conduct family counsel session patient ||| | referral resource patient | family area ||| | coordinate patient |
family patient treatment plan discharge | aftercare plan ||| | basis | coordinate lead retreat consist group therapy
| lecture question answer period | facility | finalization discharge aftercare plan ||| | participate | site
activity that relate therapy ||| | create group group sunspire health facility | focus system issue recovery ||| |
maintain documentation family counsel activity ||| | may ask complete review | utilization review | as ||| | |
college or university psychology | | or field ||| | health set ||| family therapist | | maintain licensure | lcs w |
lmh c | lmf t | aarn p. | acquire licensure ||| |license proof insurance ||| | maintain cp r aid certification ||| |
strong ||| | detail ||| | pressure as as ||| | strong | ||| | structure english language mean spell word | rule
composition | grammar ||| | principle process service ||| include assessment| standard service | evaluation
satisfaction ||| | behavior performance | difference | personality | | learn motivation | research method |
assessment treatment disorder ||| | patient | patient service resolve issue ||| | acumen ||| | car f standard ||| |
problem review develop evaluate option implement solution ||| | logic reason identify strength weakness solution |
conclusion or approach problem ||| | cost benefit action choose ||| | handle priority urgency ||| | communication | |
presentation ||| | | people ||| as||| | other | reaction | understand react ||| as | adjust action relation other |||
| bring other try reconcile difference||
Um ein Modell für Textdaten zu erstellen, müssen wir normalerweise Freiformtext in numerische Merkmalsvektoren umwandeln. In unserem Experiment verwenden wir das Modul Extract N-Gram Features from Text, um die Textdaten in ein solches Format umzuwandeln. Dieses Modul nimmt eine Spalte mit durch Leerzeichen getrennten Wörtern und berechnet ein Wörterbuch von Wörtern oder N-Grammen von Wörtern, die in Ihrem Datensatz vorkommen. Dann zählt es, wie oft jedes Wort oder N-Gramm in jedem Datensatz vorkommt, und erstellt aus diesen Zählungen Merkmalsvektoren. In unserem Experiment haben wir die N-Gramm-Größe auf 2 gesetzt, so dass unsere Merkmalsvektoren einzelne Wörter und Kombinationen aus zwei aufeinander folgenden Wörtern enthalten.

Wir wenden die TF-IDF-Gewichtung (Term Frequency Inverse Document Frequency) auf die Anzahl der N-Gramme an. Bei diesem Ansatz werden Wörter gewichtet, die in einem einzelnen Datensatz häufig vorkommen, aber im gesamten Datensatz selten sind. Weitere Optionen sind die binäre, TF- und Graph-Gewichtung.
Solche Textmerkmale haben oft eine hohe Dimensionalität. Wenn Ihr Korpus beispielsweise 100.000 eindeutige Wörter enthält, hat Ihr Merkmalsraum 100.000 Dimensionen, oder mehr, wenn N-Gramme verwendet werden. Das Modul Extract N-Gram Features bietet Ihnen eine Reihe von Optionen zur Reduzierung der Dimensionalität. Sie können Wörter ausschließen, die kurz oder lang, zu selten oder zu häufig sind, um einen signifikanten Vorhersagewert zu haben. In unserem Experiment schließen wir N-Gramme aus, die in weniger als 5 Datensätzen vorkommen.
Außerdem verwenden wir die Merkmalsauswahl, um nur die Werte zu erhalten, die am stärksten mit unserer Zielvorhersage korreliert sind. Wir verwenden die Chi-Squared-Merkmalsauswahl, um 50000 Merkmale auszuwählen. Wir können das Vokabular der ausgewählten Wörter oder N-Gramme anzeigen, indem wir auf die rechte Ausgabe des Moduls N-Gramme extrahieren klicken.
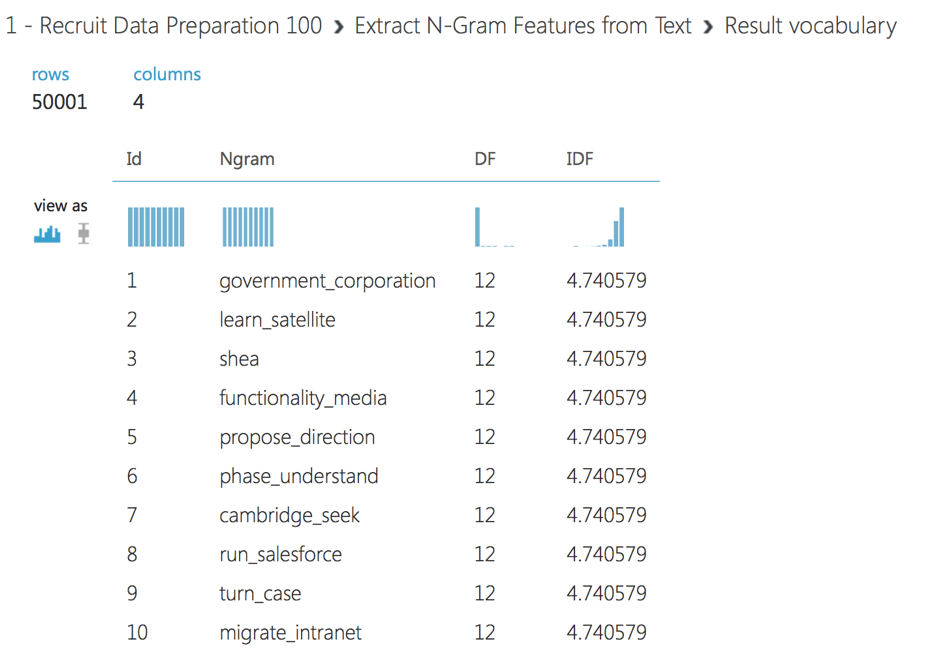
Wir verwenden das Modul Multiclass Neural Network, um ein neuronales Netzmodell zu erstellen, das zur Vorhersage eines Ziels mit mehreren Werten verwendet werden kann. Außerdem verwenden wir das Modul Tune Model Hyperparameters, um Modelle mit verschiedenen Kombinationen von Einstellungen zu erstellen und zu testen, um die optimalen Hyperparameter für die gegebene Vorhersageaufgabe und die Daten zu bestimmen.
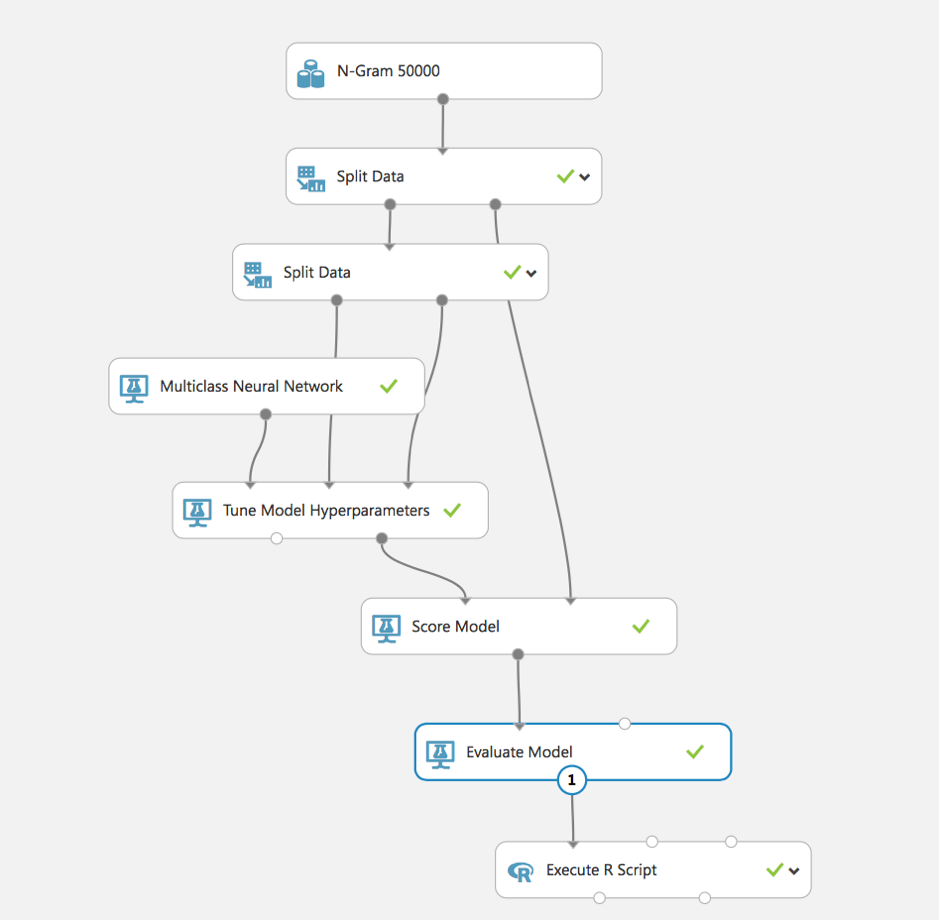
Zunächst werden die Daten in einen Trainings- und einen Testdatensatz aufgeteilt, d. h. es wird ein Teil der Daten ausgewählt, der nicht in den Trainingsprozess einbezogen wird, sondern als Testdaten für die Berechnung der Genauigkeit verwendet wird.
Im zweiten Schritt wird der Trainingsdatensatz auch für die Abstimmung der Hyperparameter des Modells aufgeteilt. Danach konfigurieren wir das Hauptmodell unseres Experiments – das Multiclass Neural Network.
Nach dem Training können wir das Modell bewerten und auswerten, um die erhaltene Genauigkeit zu analysieren.
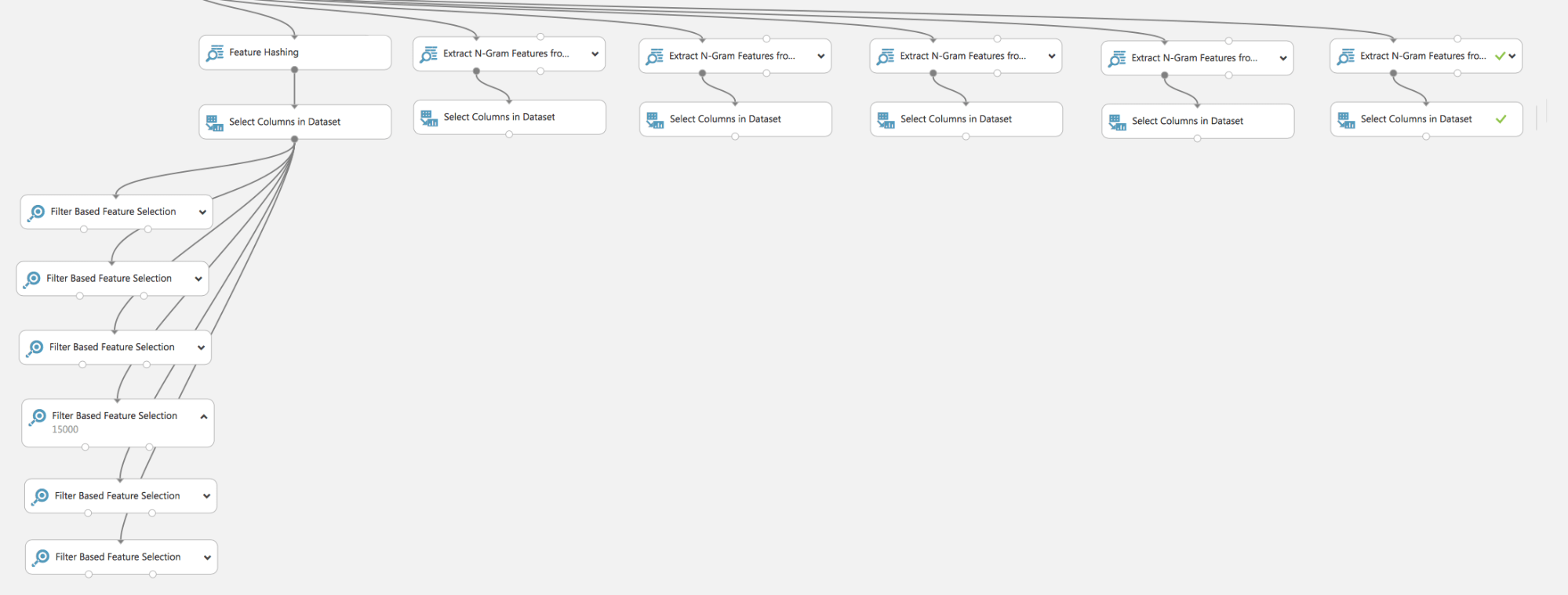
Wie wir sehen, haben wir in wenigen, relativ einfachen Schritten ein Modell zur Lösung eines praktischen Problems erstellt. Natürlich wurden einige Schritte ausgelassen, zum Beispiel die Suche nach der optimalen Textverarbeitungsmethode TF / TF-IDF und deren Parameter:
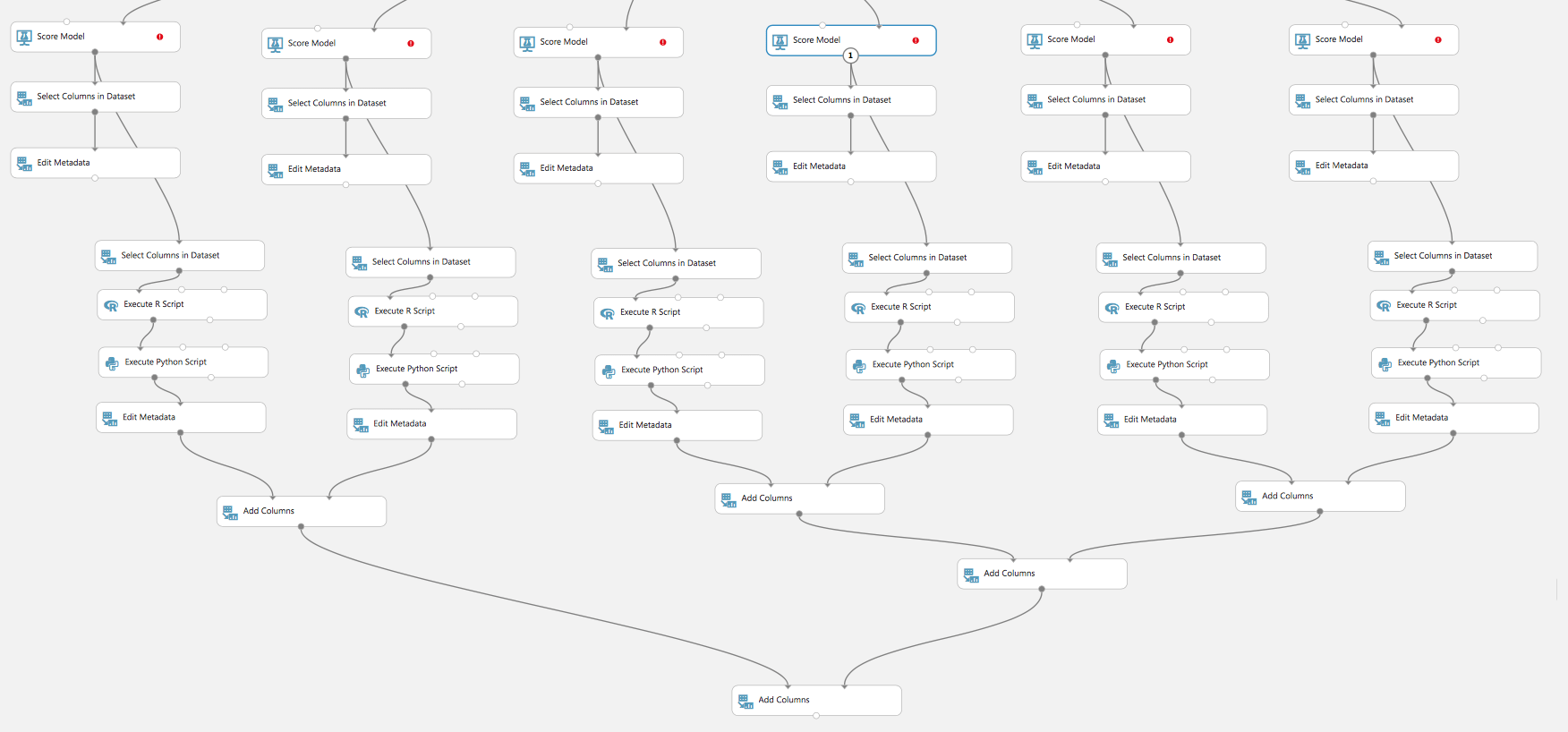
Oder die Qualität der verschiedenen Modelle zu vergleichen:
In diesem Artikel haben wir versucht, ein Beispiel für die Verwendung von ML und Azure ML Studio zur Lösung eines praktischen Problems zu zeigen. Natürlich haben wir es nur kurz gezeigt – denn die Entwicklung von Modellen für die Verarbeitung natürlicher Sprache ist ein Thema für ein ganzes Buch, und der Artikel kann zu einem Lehrbuch für ML, NLP, Azure ML Studio werden.
Aber die Hauptsache ist, dass wir bewiesen haben, dass es möglich ist, solche Modelle einfach und schnell zu erstellen, wenn man die anfänglichen ML-Kenntnisse hat und das demonstrierte Werkzeug – Azure ML Studio – dies ermöglicht.
Natürlich haben wir nicht alle Aspekte von ML und ML Studio abgedeckt, wir haben andere Modelltypen nicht berücksichtigt, haben nicht gezeigt, wie man die Parameter von Modellen effektiv auswählt – von einfachen logischen Regressionen bis zu neuronalen Netzen. Wir haben nicht gezeigt, wie man neuronale Netze mit verschiedenen Arten von Aktivierungsfunktionen und mehrschichtigen Netzen aufbaut. All dies kann im nächsten Artikel behandelt werden.
Über Redwerk
Redwerk ist ein Outsourcing-Unternehmen für die Entwicklung von Softwareprodukten, das sich auf die Bereitstellung ultimativer IT-Lösungen für Unternehmen jeder Größe spezialisiert hat. Unsere Schwerpunktbranchen sind E-Commerce, Business Automation, E-Health, Media & Entertainment, E-Government, Game Development, Startups & Innovation. Eine unserer Stärken, die wir im Laufe unserer langjährigen Berufserfahrung erworben haben, ist die Bereitstellung von Cloud-Computing-Technologie für Unternehmen. Wir optimieren Workflow-Prozesse und nutzen das beste Toolkit für diese Zwecke – Azure Application Development Service. Um die Macht der hochmodernen digitalen Fähigkeiten zu entfesseln, stellen Sie ein engagiertes Team ein, das wir innerhalb von Jahren gründlich zusammengestellt haben, um ein Problemlöser für die täglichen und strategischen Probleme von Unternehmen zu werden.
