
Das maschinelle Lernen wird bei einer Vielzahl von Geschäftsaufgaben eingesetzt – von der Aufdeckung von Betrug über die Auswahl der Zielgruppe und Produktempfehlungen bis hin zur Produktionsüberwachung in Echtzeit, der Analyse der Tonalität von Texten und der medizinischen Diagnostik. Es kann die Aufgaben übernehmen, die aufgrund der riesigen zu verarbeitenden Datenmenge nicht manuell durchgeführt werden können. Bei einer großen Datenmenge deckt das maschinelle Lernen manchmal nicht offensichtliche Abhängigkeiten auf, die bei einer willkürlichen, strengen manuellen Prüfung nicht erkannt werden können. In diesem Fall ergibt die Kombination solcher „schwachen“ Beziehungen perfekt funktionierende Vorhersagemechanismen.
Der Prozess des Lernens aus den Daten und die anschließende Anwendung des Wissens zur Begründung künftiger Entscheidungen ist ein äußerst leistungsfähiges Instrument. Maschinelles Lernen wird schnell zum Motor einer modernen, datengesteuerten Wirtschaft.
In den letzten Jahren hat sich das maschinelle Lernen („ML“) zu einem großen Geschäft entwickelt – Unternehmen nutzen es, um Geld zu verdienen. Die angewandte Forschung entwickelt sich sowohl im industriellen als auch im akademischen Umfeld rasant, und überall suchen neugierige Entwickler nach einer Möglichkeit, ihr Erfahrungsniveau in diesem Bereich zu erhöhen. Dennoch übersteigt die entstehende Nachfrage bei weitem die Geschwindigkeit, mit der gute Techniken und Werkzeuge auf den Markt kommen.
In diesem Beitrag möchten wir beschreiben, wie Sie Microsoft Azure Machine Learning Studio verwenden können, um Modelle für maschinelles Lernen zu erstellen, und auf welche Probleme Sie bei der Verwendung von Azure ML stoßen könnten und wie Sie diese umgehen können.
Werkzeuge und Grundlagen
Mit Machine Learning Studio können Sie schnell Modelle erstellen, sie trainieren und die für Ihre Aufgabe am besten geeigneten auswählen. Der große Vorteil dieser Plattform ist die Schnelligkeit, mit der sie gemeistert werden kann, was für ML-Anfänger von Vorteil ist. Aber auch für erfahrene Entwickler bietet die Plattform viele Möglichkeiten, vom Cloud Computing (das die Verarbeitung großer Datenmengen ermöglicht) bis zur einfachen Bereitstellung des trainierten Modells als Webdienst.
Sie können die Plattform oder sogar ML im Allgemeinen mit einem kostenlosen Microsoft-Konto erkunden, was zwar einige Einschränkungen mit sich bringt, Ihnen aber ermöglicht, sich mit dem System vertraut zu machen. Außerdem eignet sich ein kostenloses Konto für die Erstellung von Modellen für kleine Datenmengen.
Machen wir uns nun mit der Plattform selbst vertraut. Beginnen Sie mit der Erstellung eines Kontos in Azure Machine Learning Studio und sehen Sie sich das Menü an:

Hier haben wir mehrere Registerkarten:
- Projekte – stellen Gruppen von Experimenten dar
- Experimente – ähnlich wie bei den ipython-Notebooks
- Webdienste
- Notizbücher – ipython Notizbücher
- Gespeicherte Daten
- Modelle
- Einstellungen
Achten Sie auf die Registerkarte „Einstellungen“:
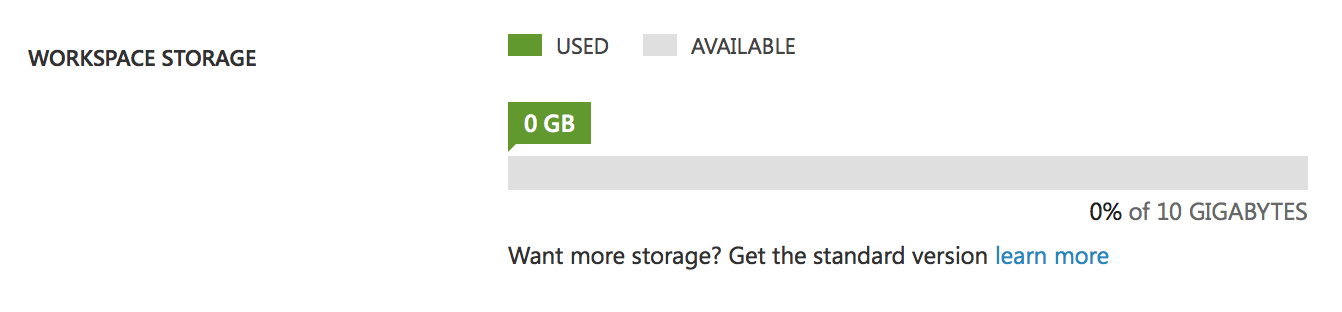
Dies ist unser freier Speicherplatz für Daten, Modelle und Experimente. 10 GB Speicherplatz ist eine der Einschränkungen des kostenlosen Kontos. Man könnte meinen, dass das ausreicht, aber bedenken Sie, dass Studio alle Zwischendaten der Experimente speichert, d.h. wenn Sie ein Experiment mit einem Datenvolumen von 1 GB haben, dann ist nach mehreren Änderungen oder dem Start des Experiments Ihre Festplatte voll und Sie müssen die Zwischendaten löschen. Bei einem kostenpflichtigen Konto gibt es diese Einschränkung nicht, Sie haben einen fast unendlichen Speicherplatz. Außerdem gibt es einen weiteren Unterschied zwischen den Konten: Mit dem kostenlosen Konto können Sie jeweils nur ein Experiment ausführen, d. h. Sie haben nur einen Thread, während das Premium-Konto die Möglichkeit bietet, mehrere Experimente gleichzeitig auszuführen oder parallele Prozesse innerhalb eines Experiments zu erstellen.
Erstellen Sie Ihr erstes Experiment
Erstellen wir ein Experiment und machen wir uns mit dem Prozess der Modellerstellung vertraut.
Wählen Sie – fügen Sie das Experiment hinzu und suchen Sie ein Beispiel für Textklassifizierung.
Studio wird ein Experiment erstellen und die Daten automatisch herunterladen.
Hier ist unser erstes Experiment:
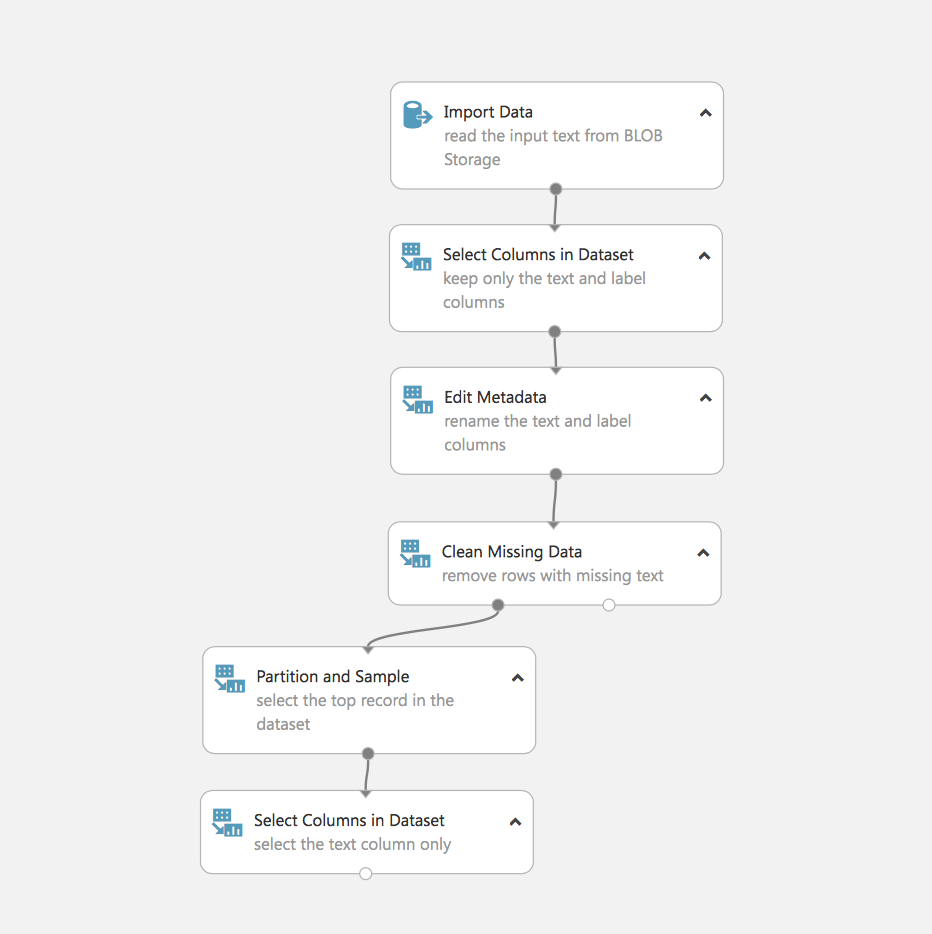
Schauen wir uns an, was hier passiert. Wir sehen die erste Aufgabe, mit der sich ML befassen muss, nämlich die Verarbeitung und Aufbereitung von Daten.
- Laden der Daten (in unserem Fall sind sie in Azure Blob gespeichert)
- Auswählen der erforderlichen Felder
- Bearbeiten von Metadaten
- Löschen von Daten mit fehlenden Feldern
- Aufteilung der Daten
Führen Sie das Experiment aus und untersuchen Sie die gesammelten Daten:
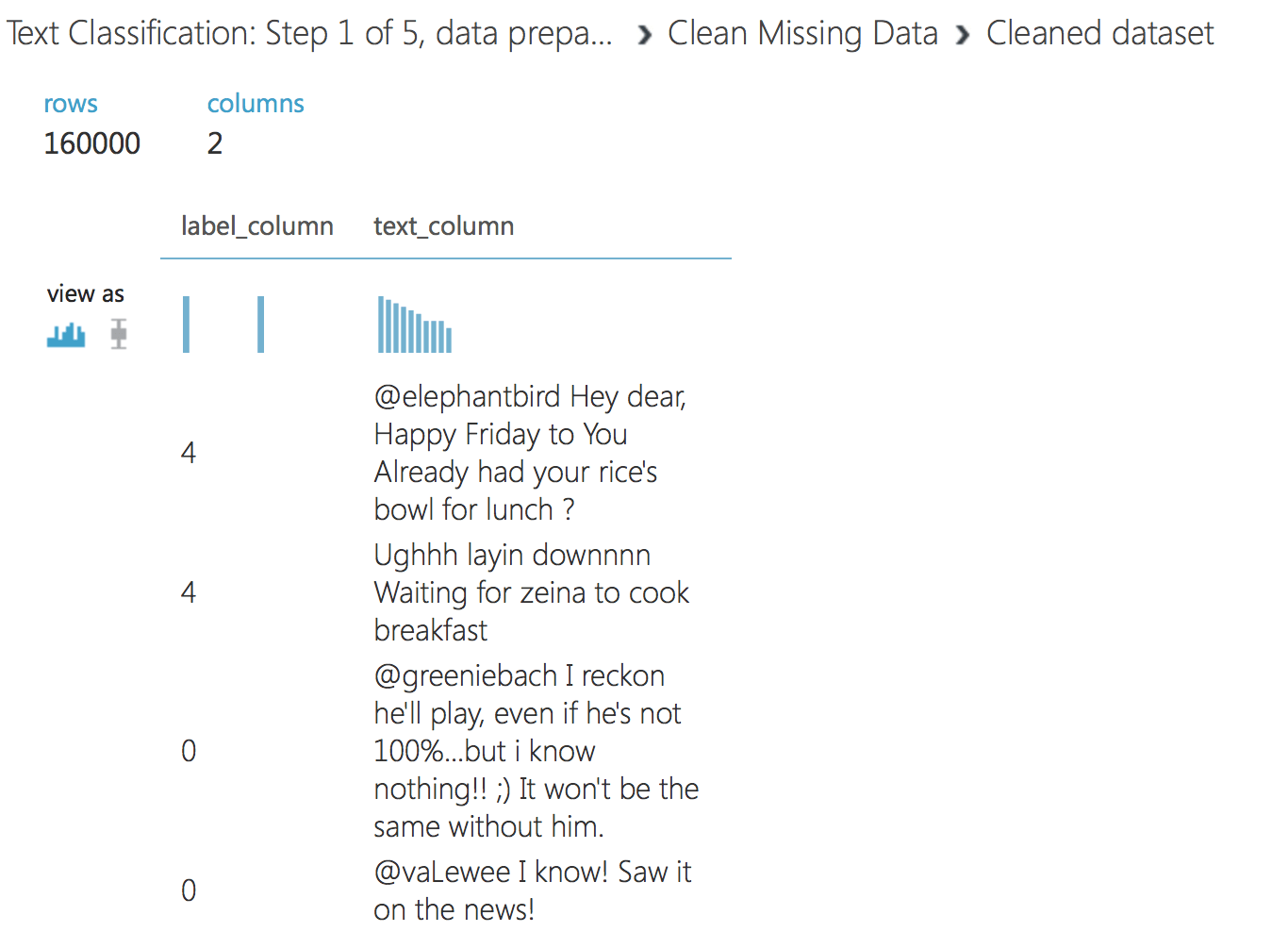
Wir haben die Daten vorbereitet und sind bereit, mit dem nächsten Schritt fortzufahren. Laden Sie das folgende Experiment – Textklassifikation: Schritt 2 von 5, Textvorverarbeitung
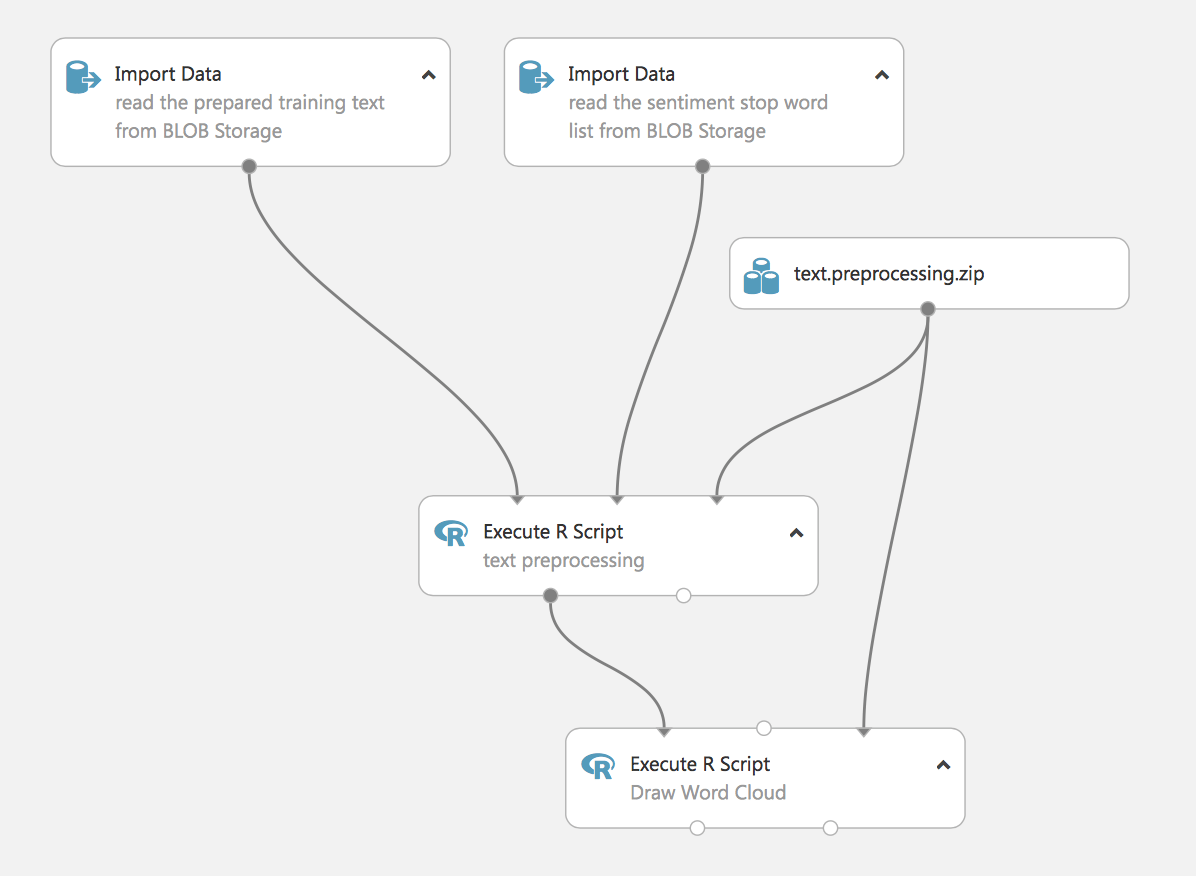
In diesem Stadium laden wir die Daten und verarbeiten sie. Bei diesem Experiment werden Skripte in R verwendet, um Stoppwörter zu entfernen (wir laden sie auch aus Blob).
Der letzte Schritt ist die Visualisierung der Wortwolke. Dies ist ein Experiment mit praktischem Wert, denn es demonstriert die Fähigkeit von Studio, R-Skripte für ML-Aufgaben zu verwenden, und wir können auch Python-Skripte in den Prozess einbinden. Im weiteren Verlauf des Artikels werden wir ein Beispiel für die Verarbeitung von Text mit Standardmethoden von Studio zeigen.
Führen wir das Experiment durch und betrachten wir die Ergebnisse.
In der Ausgabe des ersten R-Skripts sehen wir den gezeichneten Text.

Das zweite Skript erzeugt eine Wolke aus Wörtern. Dies ist manchmal für die Sichtbarkeit von Daten erforderlich.

Machen wir weiter, erstellen wir das nächste Experiment, es verwendet Daten aus dem ersten Skript des vorherigen Experiments.
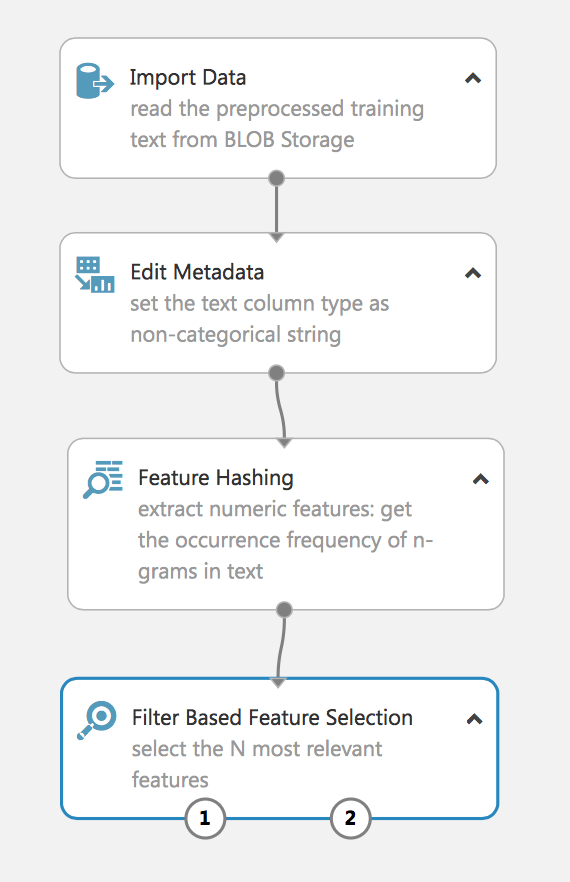
Das Experiment extrahiert die N-Gramme aus den Textdaten mithilfe der Termfrequenzmethode und wählt dann die relevantesten aus. Ein ähnliches Verfahren wird häufig zur Verarbeitung natürlicher Sprache verwendet.
Lassen Sie uns die empfangenen Daten überprüfen:

Wie Sie sehen, haben wir das Hashing-Merkmal erfolgreich aus den Textdaten extrahiert und das relevanteste Merkmal herausgefiltert. Wenn Sie keinen Filter verwenden, erhalten wir bei einer Stichprobe von 160.000 einen Vektor mit Zehntausenden von Merkmalen, was das Lernen des Modells erschwert und zu einem erneuten Training führen kann.
Das folgende Experiment demonstriert einen anderen Ansatz für die Verarbeitung von NL-TF-IDF (Term Frequency Inverse Document Frequency).
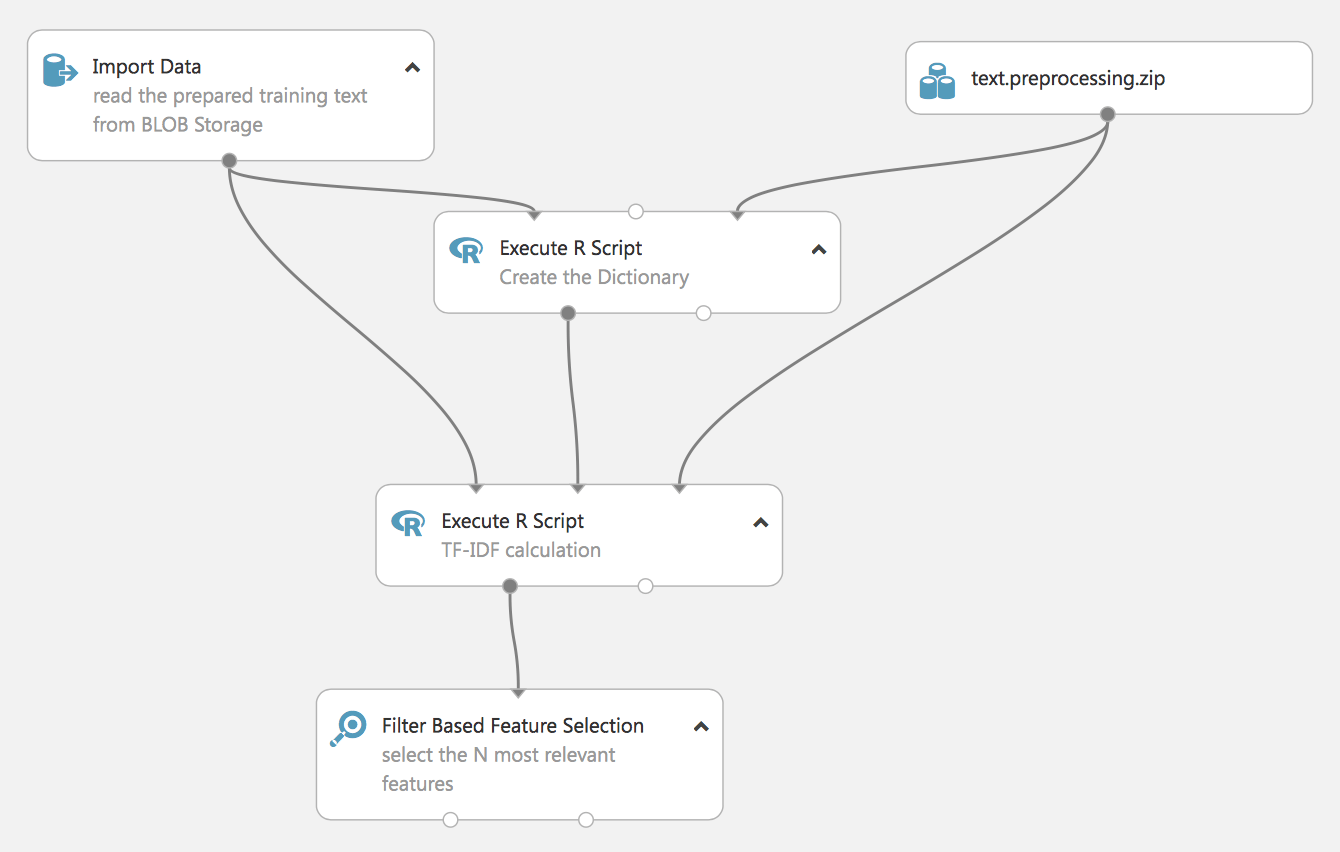
Es ist ebenfalls in der Sprache R erstellt, später werden wir zeigen, wie es mit Standard-Studio-Tools durchgeführt werden kann.
Das Ergebnis des Experiments wird ebenfalls der relevanteste Merkmalsvektor sein, der jedoch auf einem zuvor erstellten Wörterbuch (das ebenfalls auf unseren Daten basiert) basiert und im Experiment nicht gezeigt wird – vergessen Sie jedoch nicht, das Wörterbuch zu speichern, da es später für die Aufbereitung echter Daten benötigt wird.
Lassen Sie uns ein Flow-Learning-Modell erstellen.
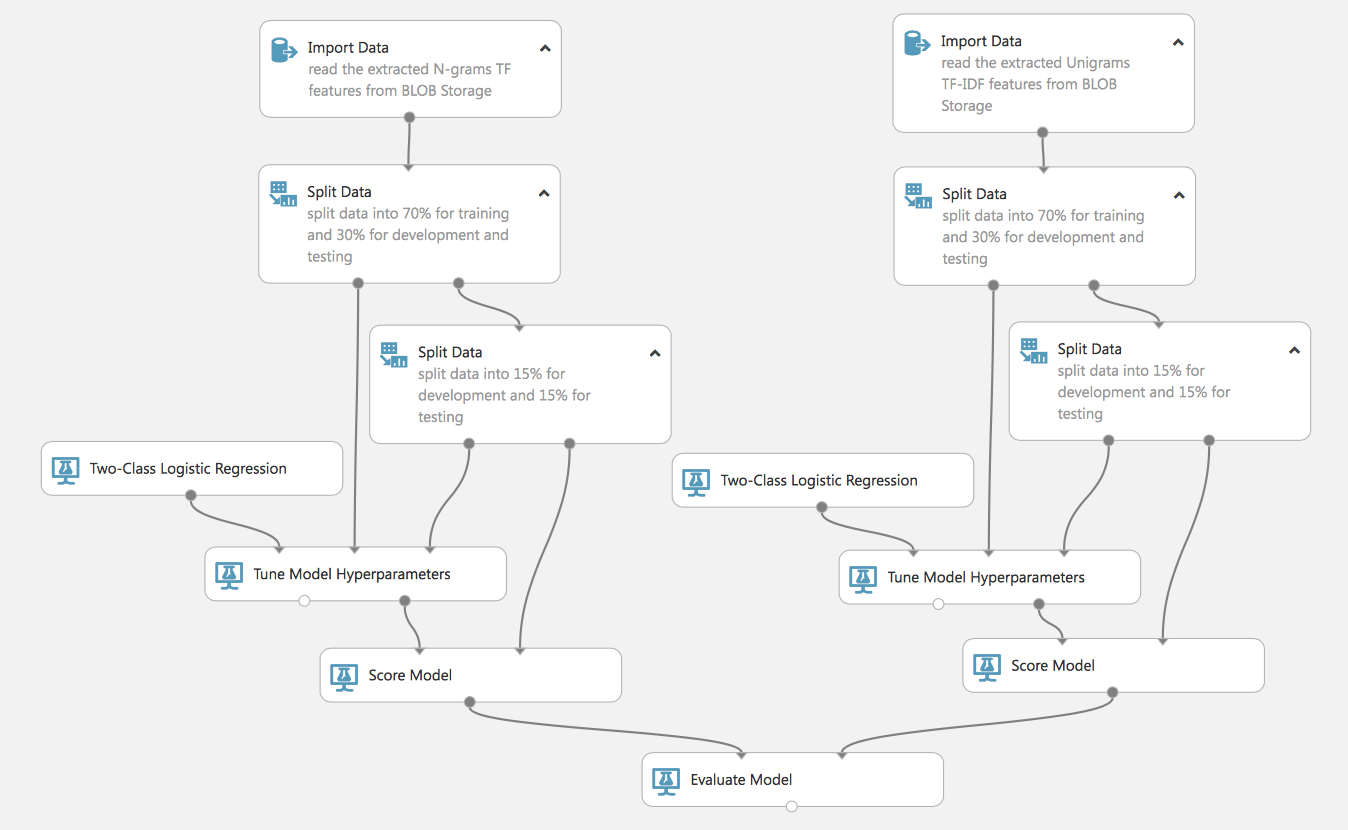
Wie Sie sehen, können wir komplexe und parallele Prozesse aufbauen (denken Sie daran, dass bei dem kostenlosen Konto alles nacheinander erfolgt, bei dem kostenpflichtigen Konto – gleichzeitig, was die Lernzeit der Modelle verkürzt). Ein solcher Ablauf ermöglicht es uns auch, 2 Modelle zu trainieren und ihre Effektivität zu vergleichen, was für die Auswahl der am besten geeigneten Modelle oder Methoden der Datenaufbereitung sehr praktisch ist.
Schauen wir uns diesen Prozess einmal genauer an. Zu Beginn gibt es 2 Datensätze, die mit verschiedenen TF- und TF-IDF-Methoden aufbereitet wurden. Diese beiden Datensätze teilen wir in Trainings- und Testdaten auf (die nicht an der Ausbildung des Modells teilnehmen und zur Bewertung seiner Qualität verwendet werden). Beachten Sie, dass wir den Testdatensatz ein zweites Mal teilen, dies ist für den nächsten Schritt notwendig.
Wir deklarieren ein Modell (in diesem Beispiel werden wir die logistische Regression verwenden), aber für eine größere Effizienz werden wir das nächste Analogon von GridSearchCV in den Prozess der Abstimmung der Modell-Hyperparameter einbeziehen (für Sklearn-Bibliotheken, die mit Python vertraut sind). Das heißt, wir legen die Parameter des Modells nicht starr fest, sondern legen die Bereichsparameter fest und übergeben sie an den Block Tune Model, der während des Trainings des Modells die effektivsten Parameter auswählt. Für diesen Block benötigen wir einen zweiten Satz von Testdaten.
Führen wir diesen Ablauf aus und untersuchen wir die Ergebnisse.
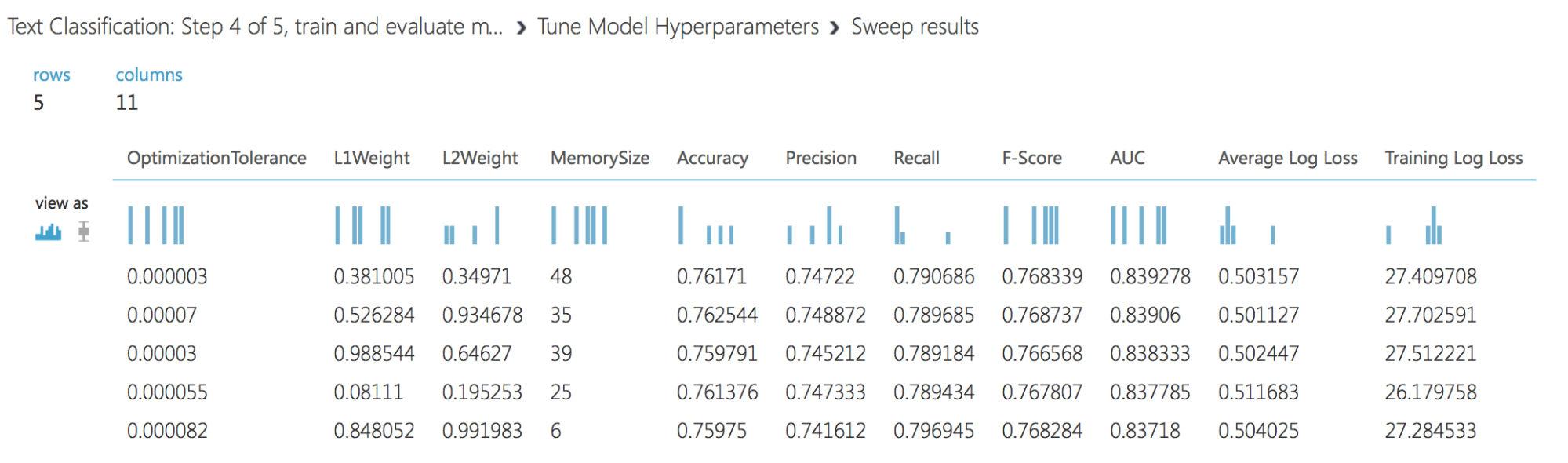
Ergebnisse von Tune Model:
Und die Parameter des besten Modells (es geht weiter zur Bewertung):
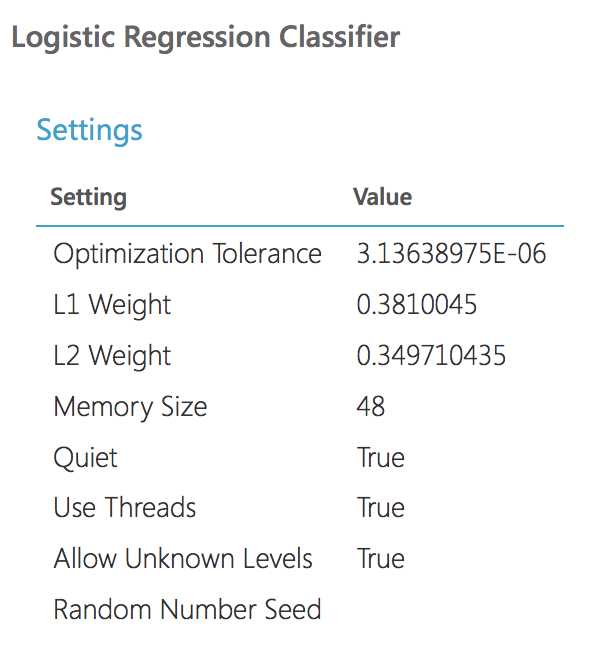
Wie wir sehen, sind die Parameter der beiden Modelle identisch. Lassen Sie uns die Qualität vergleichen. Dies ist das ROC-Diagramm für zwei Modelle:
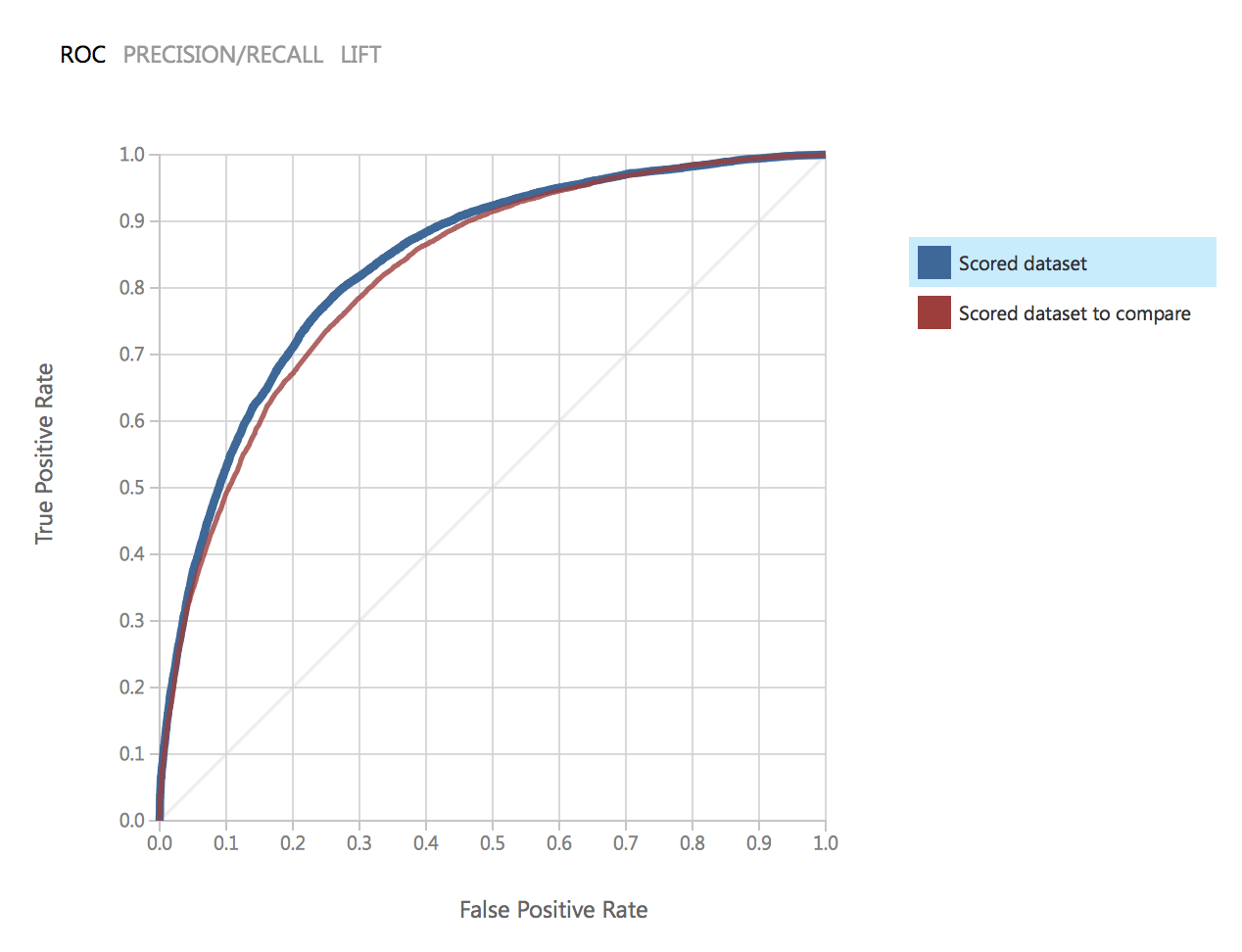
Wie man sieht, liegen die Ergebnisse beider Modelle sehr nahe beieinander und erfüllen unsere Anforderungen an die Genauigkeit.
Machen wir weiter und bauen ein Experiment auf, das die Verwendung des Modells für reale Daten (z. B. über den Webdienst) ermöglicht.
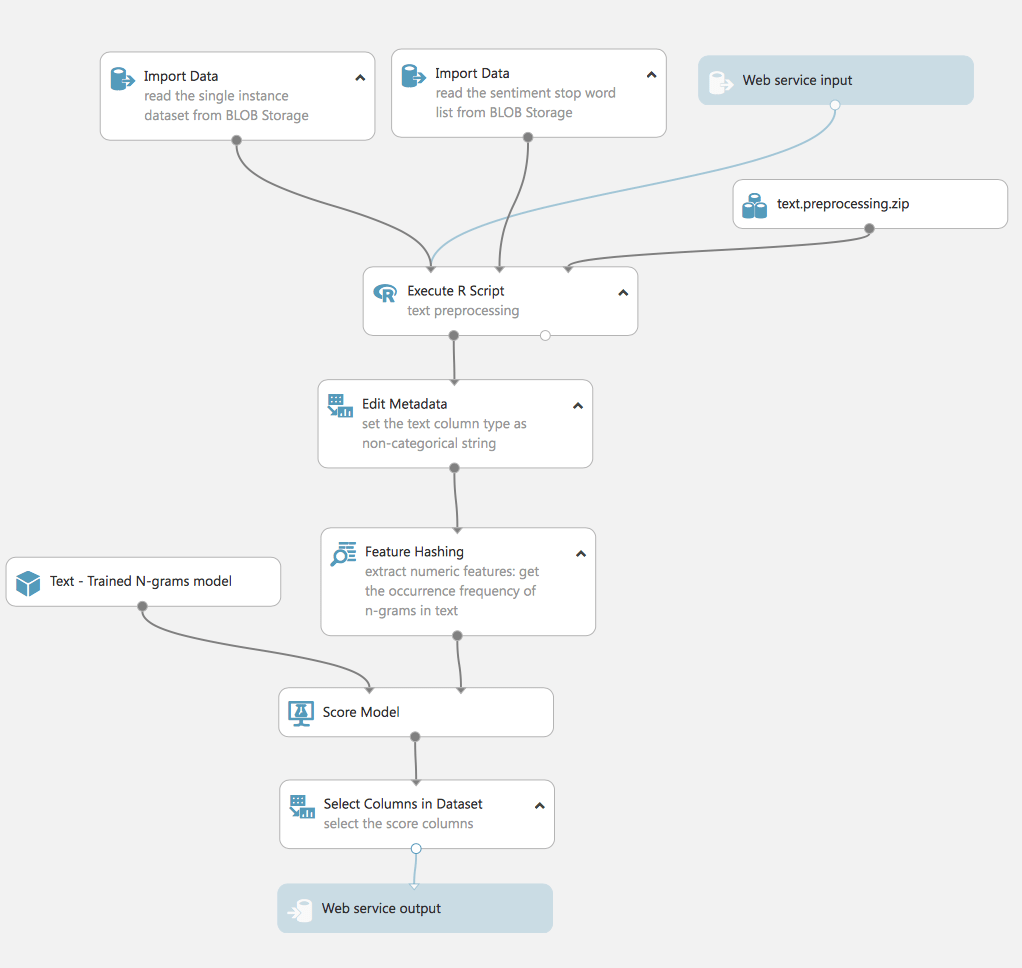
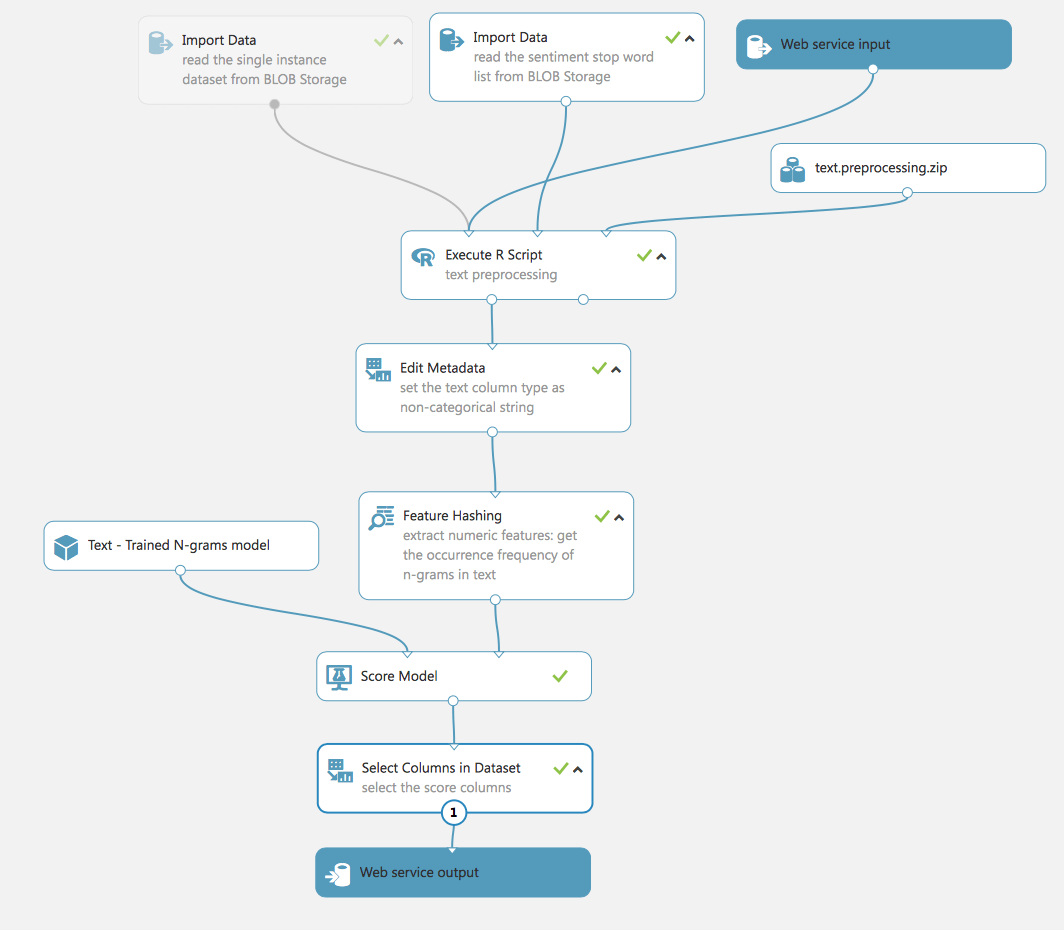
Bei diesem Experiment wird ein Modell verwendet, das mit dem TF-Verfahren trainiert wurde. Für reale Daten wiederholen wir die gleichen Schritte wie bei der Vorbereitung der Trainingsdaten: Datenbereinigung, Extraktion von Merkmalen, Filter.
Es sollte daher betont werden, dass das Experiment drei Inputs hat: Daten zum Testen (1 Zeile aus dem Originaldatensatz), den Datensatz mit Stoppwörtern zur Vorbereitung des Textes (den wir bereits in früheren Experimenten verwendet haben) und Web Service Input.
Der Webdienst-Eingang und der Webdienst-Ausgang sind genau das, was unser Experiment zu einem echten Projekt macht, das genutzt werden kann. Indem wir das Experiment in die Web Service-Ansicht umschalten, können wir das Experiment bereitstellen und von außerhalb des Studios verfügbar machen.
Tiefer gehen
In diesem Teil des Artikels haben wir einen kurzen Blick auf das Beispiel der Erstellung eines Modells geworfen und uns mit den wichtigsten Schritten der ML vertraut gemacht: Datenvorbereitung, Auswahl des Traits, Modelltraining (Auswahl der Modellparameter) und abschließende Bewertung der Ergebnisse (AUC, Precision, Recall, usw.)
Im nächsten Teil werden wir den Prozess der Erstellung eines Modells zur Lösung eines realen Problems auf der Grundlage realer Daten und zur Anwendung in einem realen Projekt betrachten.
