
Microsoft (MS) Azure ist ein Cloud-Computing-Dienst von Microsoft, der über 600 Dienste umfasst. In diesem Artikel werden wir über einen von ihnen sprechen – MS Azure Cognitive Services.
Was sind Azure Cognitive Services?
Lassen Sie uns ein wenig darüber erzählen, was sie sind. Azure Cognitive Services sind APIs, SDKs und Dienste, die entwickelt wurden, um die Erstellung von Anwendungen mit intelligenten Algorithmen zu ermöglichen, ohne dass diese von Grund auf neu erstellt werden müssen. Das Beste daran ist, dass Sie sie kostenlos nutzen können, wenn auch mit einigen Einschränkungen.
Wenn Sie gerade mit diesen Diensten herumspielen, um einen geeigneten für sich zu finden, werden Sie sich freuen zu hören, dass Sie fast alle diese Dienste auf der MS Azure-Website ausprobieren können – und das ist eine wirklich großartige Gelegenheit!
Es gibt fünf Kategorien dieser Dienste: Sehen, Sprechen, Sprache, Wissen und Suche, wie im folgenden Schema dargestellt.
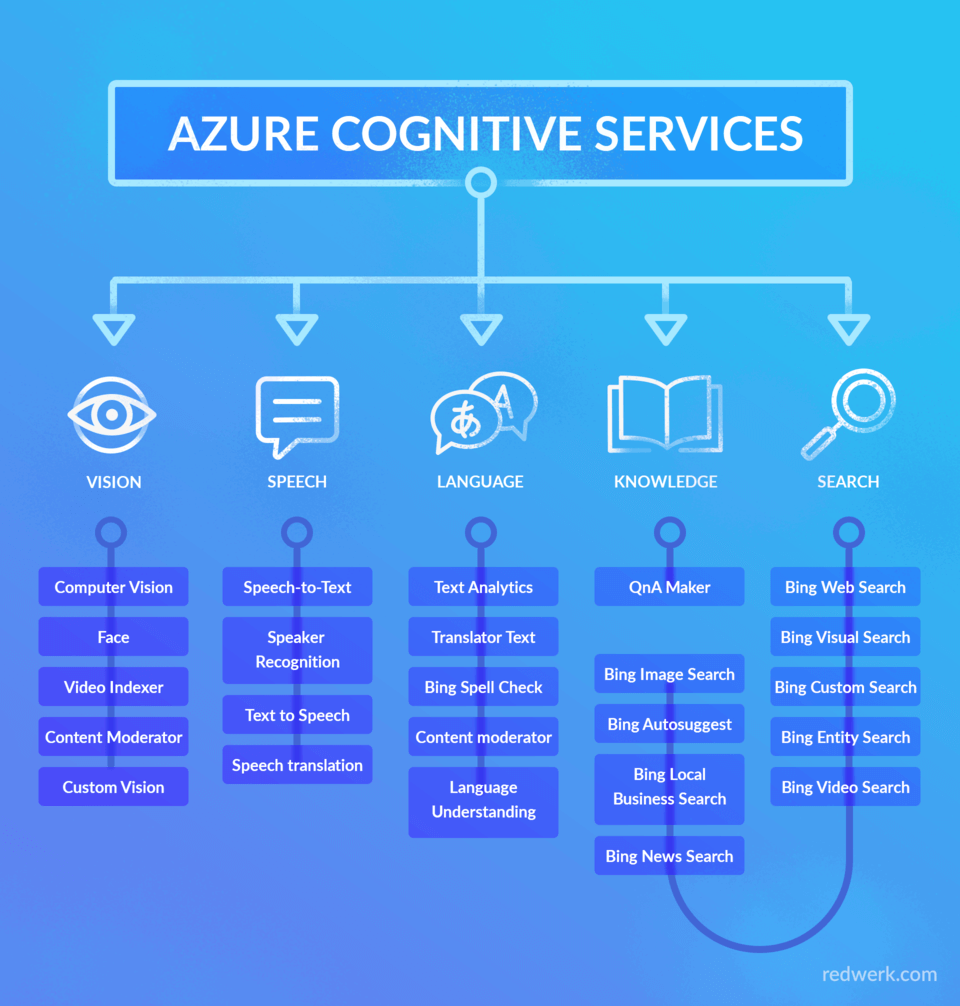
Diese fünf sogenannten Pillars fassen die Vielfalt der bereitgestellten Funktionalität zusammen und enthalten weitere Kategorien und Unterkategorien. In diesem Artikel werden wir einige Details zu jeder dieser Säulen erläutern, um Ihnen einen Überblick über Azure Cognitive Services und die damit verbundenen Möglichkeiten zu geben.
Vision
Lassen Sie uns mit Vision beginnen. Diese Gruppe von APIs bietet die Möglichkeit, Inhalte in Bildern und/oder Videos genau zu identifizieren und zu analysieren, und sie entspricht verschiedenen Anforderungen. Die Kategorien, die hier enthalten sind, sind Computer Vision, Face, Video Indexer, Content Moderator und Custom Vision. Wir werden sie alle im Detail beschreiben und Ihnen zeigen, wie sie in einem realen Szenario funktionieren.
Mit der Computer Vision API können Sie Ihre Bilder analysieren und Informationen über das Bild selbst und seinen visuellen Inhalt erhalten: Tags und Beschreibungen in vier Sprachen, Bewertungen für nicht jugendfreie und rassistische Inhalte und so weiter. Außerdem gibt es zwei APIs, mit denen Sie Wörter und sogar handgeschriebenen Text aus diesen Bildern erkennen können. Videos können Sie nahezu in Echtzeit analysieren, indem Sie Einzelbilder des Videos von Ihrem Gerät extrahieren und eine Textbeschreibung des Videoinhalts erhalten.
Wenn Sie schon immer die Gesichtserkennung und/oder –verifizierung in Ihren Anwendungen nutzen wollten, dann ist die Face API genau das Richtige für Sie. Mit ihr können Sie die Wahrscheinlichkeit überprüfen, dass zwei Gesichter zu derselben Person gehören, Gesichter auf dem Bild mit einigen Beschreibungen des Aussehens ihrer Besitzer erkennen oder Emotionen wie Wut, Verachtung, Ekel, Angst, Freude, Neutralität, Traurigkeit und Überraschung erkennen.
Azure Video Indexer ist eine Cloud-Anwendung, die auf Azure Media Analytics, Azure Search und verschiedenen kognitiven Diensten wie der Face API, Microsoft Translator, der Computer Vision API und dem Custom Speech Service basiert. Er enthält viele Funktionen, und um ihn zu nutzen, muss man kein Entwickler sein. Man kann das Video Indexer Webportal nutzen, um den Dienst zu nutzen, ohne eine einzige Zeile Code zu schreiben. Derzeit kann er Sprache in 10 Sprachen in Text umwandeln, Ihnen einige Statistiken über das Sprachverhältnis der Sprecher liefern, Gefühle und Emotionen wie Freude, Traurigkeit, Wut oder Angst erkennen, Inhalte durch die Erkennung von nicht jugendfreiem und/oder rassistischem Bildmaterial mäßigen, Audioeffekte wie Stille, Händeklatschen und so weiter erkennen. Sie können diese API auch verwenden, um Workflows auszulösen oder Aufgaben zu automatisieren, indem Sie bestimmte Phrasen oder visuelle Effekte erkennen.
Die Azure Content Moderator API ist ein kognitiver Dienst, der die Möglichkeit bietet, Texte, Bilder und Videoinhalte auf unerwünschte Inhalte zu überprüfen. Wird solches Material gefunden, wird der Inhalt mit Kennzeichnungen versehen, die Ihre Anwendung dann verarbeiten muss. Neben der maschinellen Erkennung können Sie auch einen hybriden Prozess zur Moderation von Inhalten wählen, der als „Human Review Tool“ bezeichnet wird, falls die Vorhersage mit einem realen Kontext abgemildert werden soll.
Die letzte Möglichkeit ist Custom Vision (bitte beachten Sie, dass sich diese Funktion zum Zeitpunkt der Erstellung dieses Artikels noch im Vorschaumodus befindet). Die Azure Custom Vision API ist etwas komplizierter als Computer Vision und ermöglicht es Ihnen, Ihre eigenen Klassifizierungen zu erstellen. Das bedeutet, dass Sie den Algorithmus auf Ihre Bilder mit den richtigen Tags trainieren müssen. Während des Trainings berechnet der Algorithmus seine eigene Genauigkeit, indem er sich selbst mit denselben Daten testet. Danach können Sie den Algorithmus testen, neu trainieren und ihn schließlich verwenden, um neue Bilder entsprechend den Anforderungen Ihrer Anwendung zu klassifizieren, oder Sie können das Modell zur Offline-Nutzung exportieren. Dieses Training können Sie entweder über eine webbasierte Schnittstelle oder mithilfe einer Reihe von SDKs durchführen.
Die zweite Kategorie, über die wir sprechen werden, ist Sprache, die so beliebte Funktionen wie Sprache-zu-Text (auch Spracherkennung oder Transkription genannt), Text-zu-Sprache (Sprachsynthese) und Sprachübersetzung bietet. Mit der Sprachtranskription können Sie gesprochene Audiodaten entweder aus den aufgezeichneten Dateien oder in Echtzeit in Text umwandeln. Der Dienst kann Ihnen Zwischenergebnisse der erkannten Wörter liefern und automatisch das Ende der Rede erkennen. Die Spracherkennung ermöglicht die Entwicklung von sprachgesteuerten intelligenten Anwendungen sowie die Überprüfung der Persönlichkeit oder die Identifizierung des Sprechers.
Die Text-to-Speech-API bietet die Möglichkeit, Ihren Text in Audio zu übersetzen, und zwar so, dass er von einem echten Menschen kaum zu unterscheiden ist. Sie unterstützt mehr als 75 Stimmen in mehr als 45 Sprachen und Regionen.
Mit der Speech Service API können Sie Ihren Anwendungen eine Sprachübersetzung hinzufügen, sowohl für Sprache-zu-Sprache als auch für Sprache-zu-Text-Übersetzung. Wie in der Microsoft-Dokumentation erwähnt, verwendet die Sprachübersetzungs-API die gleichen Technologien, die auch in verschiedenen Microsoft-Produkten und -Diensten zum Einsatz kommen. Dieser Dienst wird bereits von Tausenden von Unternehmen weltweit in ihren Anwendungen und Arbeitsabläufen genutzt.
Sprache
Der Bereich Sprache besteht aus APIs wie Textanalyse, Übersetzertext, Bing-Rechtschreibprüfung, Content Moderator (der auch ein Teil von „Vision“ ist) und Sprachverständnis.
Mit der Textanalyse-API können Sie Ihren Text analysieren, um die Sprache, die Stimmung, die Schlüsselsätze und die Entitäten des Textes zu identifizieren. Translator API ist ein neuronaler maschineller Übersetzungsdienst, der Ihnen die Möglichkeit der Text-zu-Text-Übersetzung in mehr als 60 Sprachen bietet.
Benötigen Sie eine Rechtschreibprüfung in Ihrer Anwendung unter Berücksichtigung des Kontexts? Dann wird es Sie freuen zu hören, dass Bing Spell Search API Ihnen diese Möglichkeit bietet, einschließlich der Verwendung spezifischer Korrekturen für Dokumente (fügt Großschreibung, grundlegende Zeichensetzung usw. für die Dokumenterstellung hinzu) und die Websuche (ist „aggressiver“, um bessere Suchergebnisse zu liefern).
Und das Sprachverständnis (LUIS) – es handelt sich um einen Cloud-basierten API-Dienst, der Ihnen helfen kann, die Konversation des Benutzers in natürlicher Sprache zu analysieren und die Gesamtbedeutung und detaillierte Informationen zu liefern. Eine übliche Client-Anwendung für LUIS ist ein Chatbot, aber es kann auch für Social-Media-Anwendungen, Chatbots, sprachgesteuerte Desktop-Anwendungen usw. verwendet werden.
Wissen
Knowledge API besteht nur aus Q&A Maker – einem Cloud-basierten API-Dienst, der eine großartige Funktionalität zur Erstellung eines Frage-und-Antwort-Dienstes aus halbstrukturierten Inhalten wie FAQ-Dokumenten, URLs und Produkthandbüchern bietet. Sie können ihn über den Bot oder die Anwendung nutzen, um Ihren Nutzern die Möglichkeit zu geben, in Sekundenbruchteilen Antworten zu erhalten, ohne die FAQ lesen oder auf eine Antwort warten zu müssen. Der Dienst antwortet, indem er eine Frage mit der bestmöglichen Antwort aus den Fragen und Antworten in Ihrer Wissensdatenbank abgleicht.
Suche
Mit dieser Gruppe von APIs können Anwendungen erstellt werden, die eine leistungsstarke Suche im Web ohne Werbung ermöglichen. Alle APIs haben ihre eigenen Kategorien, wie z. B. die Videosuche oder die Websuche, und bieten je nach Kategorie verschiedene Arten von Suchvorgängen an, die Ihre Anwendung sogar auf Ihre Bedürfnisse zuschneiden können. Unter ihnen finden Sie Sucharten wie Nachrichten, Video, Bildersuche, vollständige Websuche ohne Werbung, Autosuggest oder sogar visuelle Suche nach visuellem Inhalt.

Sicherlich kann jeder dieser Dienste in einem eigenständigen Artikel mit einem ausführlichen Überblick und Beispielen beschrieben werden, und ohne Zweifel verdienen sie es alle. Um jedoch dem Induktionscharakter des vorliegenden Artikels Rechnung zu tragen, haben wir beschlossen, zwei von ihnen auszuwählen und einige Beispiele für ihre Verwendung zu zeigen. Lassen Sie uns also ein wenig mit der Emotionserkennung und der Sprachtranskriptions-API üben.
Erkennung von Emotionen
Wenn Sie sich schon einmal mit diesem Thema beschäftigt haben, haben Sie wahrscheinlich von der Azure Emotion API gehört, die früher für die Emotionserkennung verwendet wurde. Am 15. Februar 2019 wird diese API veraltet sein, deshalb werden wir in diesem Abschnitt diese Fähigkeit als Teil der Gesichtserkennungs-API überprüfen, die sie ersetzen wird.
Voraussetzungen:
- Face API-Abonnementschlüssel. Es gibt mehrere Möglichkeiten, ihn zu erhalten: Eine davon ist die Verwendung des Testschlüssels, den Sie auf der Microsoft-Seite „Try Cognitive Services“ erhalten oder ein Cognitive Service-Konto erstellen können. Für die zweite Option benötigen Sie außerdem ein Azure-Abonnement. Lassen Sie sich davon nicht abschrecken, Azure bietet eine großartige Möglichkeit, ein kostenloses Konto zu erstellen und kostenlose Tier-Pläne für die Bedürfnisse von Entwicklern zu nutzen.
- Im vorliegenden Beispiel wird .NET Core verwendet, Sie können also jede IDE nach Ihrem Geschmack verwenden. Sie können auch ein Projekt mit .NET Framework erstellen, in diesem Fall benötigen Sie Visual Studio 2015 oder 2017.
- Ein Bild im Format JPEG, PNG, GIF (wird für das erste Bild verwendet) oder BMP mit einer Dateigröße von 1KB bis 6MB. Es können bis zu 64 Gesichter für ein Bild zurückgegeben werden, wenn ihre Größe 36×36 bis 4096×4096 Pixel beträgt. Es gibt einige Fälle, in denen Gesichter aufgrund von großen Gesichtswinkeln oder falscher Bildausrichtung nicht erkannt werden können – berücksichtigen Sie dies bei der Auswahl eines Bildes für die Analyse.
Erstellen Sie in der IDE eine neue Console App (.NET Core) und nennen Sie sie „CognitiveServicesEx“ (oder was auch immer Sie wollen, behalten Sie es einfach im Hinterkopf, dann werden Sie den Code aus dem Beispiel kopieren). Wir werden das NuGet-Paket „Newtonsoft.Json“ für die Anzeige einer Antwort verwenden, also klicken Sie mit der rechten Maustaste auf den Projektnamen und wählen Sie aus dem Kontextmenü „Manage NuGet packages…“. Suchen Sie dieses Paket in der Liste und installieren Sie es. Danach ersetzen Sie in der erstellten Projektdatei „Program.cs“ den Inhalt durch den folgenden Code:
using Newtonsoft.Json.Linq;
using System;
using System.IO;
using System.Net.Http;
using System.Net.Http.Headers;
namespace CognitiveServicesEx {
class Program {
static void Main(string[] args) {
GetEmotionsFromLocalImage();
Console.ReadLine();
}
static async void GetEmotionsFromLocalImage() {
string imageFilePath =
@"D:\practise\CognitiveServicesExample\CognitiveServicesEx\Resources\IMG_1556.jpg";
if (File.Exists(imageFilePath)) {
try {
Console.WriteLine("\nAnalyzing....\n");
HttpClient client = new HttpClient();
client.DefaultRequestHeaders.Add("Ocp-Apim-Subscription-Key",
"25eb4c2f2d0e41eda1985b8a13c56e30");
string requestParameters = "returnFaceId=true" +
"&returnFaceLandmarks=false" +
"&returnFaceAttributes=smile,emotion";
string uri =
$"https://westcentralus.api.cognitive.microsoft.com" +
$"/face/v1.0/detect?{requestParameters}";
HttpResponseMessage response;
using (FileStream fileStream = new FileStream(imageFilePath,
FileMode.Open,
FileAccess.Read)) {
BinaryReader binaryReader = new BinaryReader(fileStream);
byte[] byteData = binaryReader.ReadBytes((int)fileStream.Length);
using (ByteArrayContent content = new ByteArrayContent(byteData)) {
content.Headers.ContentType =
new MediaTypeHeaderValue("application/octet-stream");
response = await client.PostAsync(uri, content);
string contentString = await response.Content.ReadAsStringAsync();
Console.WriteLine("\nResponse:\n");
Console.WriteLine(JToken.Parse(contentString).ToString());
Console.WriteLine($"\nPress any key to exit...\n");
}
}
}
catch (Exception e) {
Console.WriteLine($"\n{e.Message}\nPress any key to exit...\n");
}
}
else {
Console.WriteLine("\nFile does not exist.\nPress any key to exit...\n");
}
}
}
}Erstellen Sie in der IDE eine neue Console App (.NET Core) und nennen Sie sie „CognitiveServicesEx“ (oder was auch immer Sie wollen, behalten Sie es einfach im Hinterkopf, dann werden Sie den Code aus dem Beispiel kopieren). Wir werden das NuGet-Paket „Newtonsoft.Json“ für die Anzeige einer Antwort verwenden, also klicken Sie mit der rechten Maustaste auf den Projektnamen und wählen Sie aus dem Kontextmenü „Manage NuGet packages…“. Suchen Sie dieses Paket in der Liste und installieren Sie es. Danach ersetzen Sie in der erstellten Projektdatei „Program.cs“ den Inhalt durch den folgenden Code:
Bevor Sie dieses Beispiel ausführen, werden wir dieses Stück Code für Sie aufschlüsseln. Dieses Beispiel arbeitet mit dem lokal gespeicherten Bild, dessen Pfad wir in der Variablen imageFilePath festgelegt haben. Sie können auch mit Bild-URLs arbeiten, und wir werden dieses Beispiel später noch etwas genauer betrachten.
In der Variable „requestParameters“ legen wir fest, welche Informationen wir genau benötigen. Über diese optionalen Parameter können wir auch Alter, Geschlecht, Kopfhaltung (headPose-Parameter), Gesichtsbehaarung (facialHair-Parameter), Brille, Haare, Make-up, Okklusion, Accessoires, Unschärfe, Belichtung und Rauschen erhalten. Jeder dieser Parameter kann der Variable „requestParameters“ hinzugefügt werden, die durch ein Komma getrennt ist. Wir werden im Beispiel nur die Parameter Emotionen und Lächeln betrachten.
Was den Link zur API betrifft, so beachten Sie bitte, dass Sie dieselbe Region verwenden müssen, die Sie auch für den Erhalt eines Abonnementschlüssels verwendet haben. Schlüssel für kostenlose Probeabonnements werden immer in der Region „westus“ generiert. Wenn Sie also bereits solche Schlüssel verwenden, müssen Sie sich keine Sorgen machen.
Starten Sie nun die Anwendung. Für jede Art von Emotion wird eine Zahl von 0 bis 1 angezeigt. Je größer diese Zahl ist, desto stärker wird diese Emotion von einer Person ausgedrückt. Zum Testen werden wir das Foto von unserer Halloween-Firmenfeier verwenden:

Die Ergebnisse der Bildanalyse sind wie folgt:
Analysieren….
Antwort:
[{
"faceId": "8fb67a9c-e9f8-47b3-9524-865fc85f1550",
"faceRectangle": {
"top": 512,
"left": 1498,
"width": 817,
"height": 817
},
"faceAttributes": {
"smile": 0.677,
"emotion": {
"anger": 0.0,
"contempt": 0.001,
"disgust": 0.0,
"fear": 0.0,
"happiness": 0.677,
"neutral": 0.322,
"sadness": 0.0,
"surprise": 0.0
}
}
},
{
"faceId": "5b09a37d-5837-4ee7-a7f7-83f3c7d170e4",
"faceRectangle": {
"top": 815,
"left": 965,
"width": 520,
"height": 520
},
"faceAttributes": {
"smile": 0.995,
"emotion": {
"anger": 0.001,
"contempt": 0.0,
"disgust": 0.0,
"fear": 0.002,
"happiness": 0.995,
"neutral": 0.0,
"sadness": 0.0,
"surprise": 0.001
}
}
}]Drücken Sie eine beliebige Taste zum Beenden…
Ein erfolgreicher Aufruf gibt ein Array von Flächeneinträgen zurück, die nach der Größe des Flächenrechtecks in absteigender Reihenfolge geordnet sind. Jeder Gesichtseintrag enthält die folgenden Werte (abhängig von den Abfrageparametern):
- faceId – der eindeutige Identifikator des erkannten Gesichts (läuft 24 Stunden nach dem Erkennungsaufruf ab);
- faceRectangle – die Koordinaten des Rechtecks, in dem sich das Gesicht befindet;
- faceAttributes:
- smile: Intensität des Lächelns (eine Zahl zwischen 0 und 1);
- Emotion: einschließlich eines Wertes für die Intensität der Emotionen Neutral, Wut, Verachtung, Ekel, Angst, Glück, Traurigkeit und Überraschung (eine Zahl zwischen 0 und 1).
Sie können eine Liste von Fehlercodes und -meldungen in der Microsoft-Dokumentation einsehen, die meisten davon werden durch die Bildgröße, ungültige Argumente oder Links zu Bildern verursacht.
Wie wir bereits erwähnt haben, würden wir überprüfen, wie der REST-Aufruf aussehen sollte, wenn Sie das Bild per URL analysieren müssten. So einfach ist das: Sie müssen nur den URL-Parameter als HttpContent für die PostAsync-Methode hinzufügen. Die Methode „GetEmotionsFromLocalImage“ sieht in diesem Fall also wie folgt aus:
static async void GetEmotionsFromLocalImage() {
string imageFilePath =
@"D:\practise\CognitiveServicesExample\CognitiveServicesEx\Resources\IMG_1556.jpg";
if (File.Exists(imageFilePath)) {
try {
Console.WriteLine("\nAnalyzing....\n");
HttpClient client = new HttpClient();
client.DefaultRequestHeaders.Add("Ocp-Apim-Subscription-Key",
"25eb4c2f2d0e41eda1985b8a13c56e30");
string requestParameters = "returnFaceId=true" +
"&returnFaceLandmarks=false" +
"&returnFaceAttributes=smile,emotion";
string uri =
$"https://westcentralus.api.cognitive.microsoft.com" +
$"/face/v1.0/detect?{requestParameters}";
HttpResponseMessage response;
var data = new JObject {
["url"] =
$"https://docs.microsoft.com" +
$"/en-us/azure/cognitive-services/face/images/facefindsimilar.queryface.jpg"
};
var json = JsonConvert.SerializeObject(data);
var content = new StringContent(json, Encoding.UTF8, "application/json");
response = await client.PostAsync(uri, content);
string contentString = await response.Content.ReadAsStringAsync();
Console.WriteLine("\nResponse:\n");
Console.WriteLine(JToken.Parse(contentString).ToString());
Console.WriteLine($"\nPress any key to exit...\n");
}
catch (Exception e) {
Console.WriteLine($"\n{e.Message}\nPress any key to exit...\n");
}
}
else {
Console.WriteLine("\nFile does not exist.\nPress any key to exit...\n");
}
}Wie Sie sehen können, ist die Arbeit mit dieser API ein Kinderspiel. Microsoft stellt sehr leistungsfähige Dienste zur Verfügung, die wirklich einfach zu benutzen sind. Jetzt können Sie selbst mit anderen optionalen Parametern experimentieren, um einen vollständigen Überblick über die Funktionsweise und die Möglichkeiten zu erhalten.
Sprachtranskription
Die Speech-to-Text-API bietet die Möglichkeit, jedes gesprochene Audio (z. B. eine aufgezeichnete Datei, Audio vom Mikrofon usw.) in Text umzuwandeln. In unserem Beispiel werden wir versuchen, ein aufgenommenes Audiobeispiel in Text zu transkribieren.
Voraussetzungen:
- einen Speech-API-Abonnementschlüssel. Die Möglichkeiten, ihn zu erhalten, sind dieselben wie für den Vision-API-Abonnementschlüssel.
- Die IDE-Voraussetzungen sind ebenfalls dieselben wie für die Sprach-API.
- Wir werden die Transkription der aufgenommenen Datei über die REST-API prüfen, die das folgende Format haben sollte
- WAV, Codec: PCM, Bitrate: 16-bit, Abtastrate: 16 kHz, mono, Dauer bis zu 10 Sekunden;
- OGG, Codec: OPUS, Bitrate: 16-bit, Abtastrate: 16 kHz, mono, Dauer bis zu 10 Sekunden.
Die oben genannten Anforderungen an die Datei gelten nur für die REST-API und WebSocket im Speech Service. Wenn Sie längere Audiodateien erkennen müssen, verwenden Sie das Speech SDK oder die Batch-Transkription. Das Speech SDK unterstützt derzeit nur das WAV-Format mit PCM-Codec und Sie sollten dies bei der Verwendung des SDK berücksichtigen. In diesem Artikel haben wir uns für die Verwendung der REST-API entschieden, da das SDK in der Regel einfacher zu bedienen ist und außerdem eine begrenzte Anzahl von Sprachen unterstützt. Im Gegensatz dazu funktioniert die REST-API mit jeder Sprache, die HTTP-Anfragen stellen kann, und deshalb können diese Beispiele nützlicher sein.
Lassen Sie uns unser Testprogramm ein wenig abändern.
using Newtonsoft.Json.Linq;
using System;
using System.IO;
using System.Net.Http;
using System.Net.Http.Headers;
namespace CognitiveServicesEx {
class Program {
static void Main(string[] args) {
Console.WriteLine("Choose what to analyze from the following list:");
Console.WriteLine("\t1 - Image");
Console.WriteLine("\t2 - Audio");
switch (Console.ReadLine()) {
case "1":
GetEmotionsFromLocalImage();
break;
case "2":
ConvertAudioToText();
break;
}
Console.ReadLine();
}
static async void GetEmotionsFromLocalImage() {
string imageFilePath = @"D:\practise\CognitiveServicesExample\CognitiveServicesEx\Resources\IMG_1551.jpg";
string subscriptionKey = "25eb4c2f2d0e41eda1985b8a13c56e30";
string requestParameters = "returnFaceId=true&returnFaceLandmarks=false&returnFaceAttributes=smile,emotion";
string uri = $"https://westcentralus.api.cognitive.microsoft.com/face/v1.0/detect?{requestParameters}";
if (File.Exists(imageFilePath)) {
try {
Console.WriteLine("\nAnalyzing....\n");
HttpClient client = new HttpClient();
client.DefaultRequestHeaders.Add("Ocp-Apim-Subscription-Key", subscriptionKey);
HttpResponseMessage response;
using (FileStream fileStream = new FileStream(imageFilePath, FileMode.Open, FileAccess.Read)) {
BinaryReader binaryReader = new BinaryReader(fileStream);
byte[] byteData = binaryReader.ReadBytes((int)fileStream.Length);
using (ByteArrayContent content = new ByteArrayContent(byteData)) {
content.Headers.ContentType = new MediaTypeHeaderValue("application/octet-stream");
response = await client.PostAsync(uri, content);
string contentString = await response.Content.ReadAsStringAsync();
Console.WriteLine("Response:\n");
Console.WriteLine(JToken.Parse(contentString).ToString());
Console.WriteLine($"\nPress any key to exit...\n");
}
}
}
catch (Exception e) {
Console.WriteLine($"\n{e.Message}\nPress any key to exit...\n");
}
}
else {
Console.WriteLine("\nFile does not exist.\nPress any key to exit...\n");
}
}
static async void ConvertAudioToText() {
string audioFilePath = @"D:\practise\CognitiveServicesExample\CognitiveServicesEx\Resources\whatstheweatherlike.wav";
string authUri = "https://westus.api.cognitive.microsoft.com/sts/v1.0/issueToken";
string apiUri = "https://westus.stt.speech.microsoft.com/speech/recognition/conversation/cognitiveservices/v1?language=en-US&format=detailed";
string subscriptionKey = "1e907c0e08554d4aaab42f8e1f6939b0";
string token;
using (var client = new HttpClient()) {
Console.WriteLine("\nGet auth token....\n");
client.DefaultRequestHeaders.Add("Ocp-Apim-Subscription-Key", subscriptionKey);
UriBuilder uriBuilder = new UriBuilder(authUri);
var result = await client.PostAsync(uriBuilder.Uri.AbsoluteUri, null).ConfigureAwait(false);
token = await result.Content.ReadAsStringAsync().ConfigureAwait(false);
}
if (!String.IsNullOrEmpty(token)) {
Console.WriteLine("\nAnalyzing....\n");
try {
using (var client = new HttpClient()) {
using (var request = new HttpRequestMessage()) {
using (FileStream fileStream = new FileStream(audioFilePath, FileMode.Open, FileAccess.Read)) {
BinaryReader binaryReader = new BinaryReader(fileStream);
byte[] byteData = binaryReader.ReadBytes((int)fileStream.Length);
using (ByteArrayContent content = new ByteArrayContent(byteData)) {
request.Method = HttpMethod.Post;
request.RequestUri = new Uri(apiUri);
request.Content = content;
request.Headers.Add("Authorization", $"Bearer {token}");
request.Content.Headers.Add("Content-Type", "audio/wav");
using (var response = await client.SendAsync(request).ConfigureAwait(false)) {
response.EnsureSuccessStatusCode();
string contentString = await response.Content.ReadAsStringAsync();
Console.WriteLine("Response:\n");
Console.WriteLine(JToken.Parse(contentString).ToString());
Console.WriteLine($"\nPress any key to exit...\n");
}
}
}
}
}
}
catch (Exception e) {
Console.WriteLine($"\n{e.Message}\nPress any key to exit...\n");
}
}
else {
Console.WriteLine("\nAuth token not received.\nPress any key to exit...\n");
}
}
}
}Wie Sie sehen können, haben wir unser Programm ein wenig erweitert und die Möglichkeit hinzugefügt, dass der Benutzer auswählen kann, was er analysieren möchte. Werfen Sie einen Blick auf die Methode „ConvertAudioToText“ – Sie werden sehen, dass sie zwei API-URLs enthält. Normalerweise können Sie für die Sprache-zu-Text-REST-API einen Abonnementschlüssel verwenden, aber es gibt auch eine andere Option (die erforderlich ist und die einzige, die für die Text-zu-Sprache-REST-API verfügbar ist), nämlich die Verwendung eines Autorisierungs-Headers. Die Sprachtranskription wurde mit dem Authorization-Header realisiert, um Beispiele zu diversifizieren und eine breitere Überprüfung zu ermöglichen. Bei der Verwendung des Authorization: Bearer-Header verwenden, müssen Sie die Anfrage an den issueToken-Endpunkt senden. Dieser stellt Ihnen ein Token zur Verfügung, das für die Audioanalyse für die nächsten 10 Minuten gültig ist. Da das Audio das Standardbeispiel mit der Phrase „Wie ist das Wetter?“ verwendet, wurde es von der API eindeutig erkannt:
Choose what to analyze from the following list:
1 - Image
2 - Audio
2Authentifizierungs-Token abrufen….
Analysieren….
Antwort:
{
"RecognitionStatus": "Success",
"Offset": 300000,
"Duration": 15900000,
"NBest": [{
"Confidence": 0.96764832735061646,
"Lexical": "what's the weather like",
"ITN": "what's the weather like",
"MaskedITN": "what's the weather like",
"Display": "What's the weather like?"
}]
}Drücken Sie eine beliebige Taste zum Beenden…
Unserer Erfahrung nach ist das Ergebnis umso genauer, je klarer der Ton ist (ohne Rauschen usw.).
Fazit
Die Einbeziehung von künstlicher Intelligenz in Lösungen wird heutzutage immer beliebter. Und Azure von Microsoft ist einer der Giganten, der leistungsstarke KI-gestützte Dienste anbietet, die in vielen Bereichen nützlich und einfach zu implementieren und einzusetzen sind. Wenn Sie daran interessiert sind, Azure Cognitive Services für Ihre Anwendungen zu nutzen und jemanden brauchen, der Sie dabei unterstützt – kontaktieren Sie uns.
Über Redwerk
Redwerk wurde 2005 gegründet und hat sich von einem Knoten von Enthusiasten zu einer Agentur mit zwei Hauptquartieren entwickelt, die mehr als 60 digital versierte Personen beherbergt, die den Einsatz moderner Technologien beherrschen und dazu berufen sind, Hightech-Branchen auf ein völlig neues Niveau zu bringen. Wir verwenden ausschließlich fortschrittliche Tools und entwickeln fabelhafte und kreative Lösungen für Unternehmen jeder Größe auf der ganzen Welt. Redwerk ist der richtige Ort, um die Entwicklung von Individualsoftware auszulagern, denn unser technisches Know-how umfasst nicht nur die Programmierung, sondern auch Anforderungsanalyse, Architektur, UI/UX-Design, Qualitätssicherung und Tests, Wartung, Systemadministration und Support. Wenn Sie auf der Suche nach einem engagierten Team, einem maßgeschneiderten Ansatz und Transparenz sind, dann ist Redwerk genau der One-Stop-Shop, in dem Ihr Projekt pünktlich und innerhalb des Budgets realisiert wird.
