Die meisten Tutorials zu KI-Support-Agenten zeigen Ihnen den Idealfall. Sie hören genau dort auf, wo die eigentliche Arbeit beginnt – nämlich in dem Moment, in dem ein echter Kunde mit einer Frage auf Ihren Workflow trifft, die niemand vorhergesehen hat. Laut dem workflow with a question nobody anticipated. According to 7. State of Service Report von Salesforce, basierend auf 6.500 Service-Fachleuten weltweit, werden 2025 bereits 30 % der Kundendienst-Anfragen durch KI gelöst, und diese Zahl soll bis 2027 auf 50 % steigen. Die Einführung ist nicht mehr das schwierige Teil. Die Architektur schon.ch 50% by 2027. Adoption is not the hard part anymore. Architecture is.
Dieser Artikel führt Sie durch das, was tatsächlich hinter einem funktionierenden KI-Kundensupport-Agenten steckt, der mit n8n aufgebaut wurde. Wir behandeln die Kompromisse, die Sie am ersten Tag eingehen, die drei Entscheidungen, die darüber entscheiden, ob Ihr Agent skaliert, die Fehlermodi, die wir in der Produktion gesehen haben, und die Metriken, die Ihnen zeigen, dass sich die Sache auszahlt.in production, and the metrics that tell you the thing is paying off.
Warum einen Support-Agenten mit n8n bauen statt kaufen
Der Kauf eines fertigen Helpdesk-KI-Tools ist die richtige Entscheidung, wenn Sie am ersten Tag ausgereifte Analysen benötigen, keinen Entwickler für die Wartung haben oder weniger als 500 Tickets pro Monat verarbeiten. Für alle anderen beginnt es schnell Sinn zu ergeben, mit n8n zu bauen.ess fewer than 500 tickets a month. For everyone else, building on n8n starts making sense fast.
In jedem Gespräch, das wir mit Gründern und CTOs führen, die diese Entscheidung abwägen, tauchen drei Gründe auf:
- Daten bleiben, wo Sie sie wollen. Hosten Sie n8n auf Ihrer eigenen Cloud, und Kundengespräche verlassen nie Ihren Perimeter. Das ist wichtig für jeden, der unter DSGVO, HIPAA oder einem Beschaffungsteam steht, das kritische Fragen stellt.
- Ihre Systeme integrieren sich nativ. Ihre Abrechnungs-, CRM-, Ticketing- und internen Tools sprechen bereits miteinander. n8n spricht auch mit ihnen, über 400+ Connectoren und einen sauberen HTTP-Node für den Rest.or the rest.
- Kosten skalieren linear mit dem Volumen, nicht mit der Anzahl der Lizenzen. Keine Lizenzgebühren pro Agent on top Ihrer LLM-Rechnung.
Die n8n-Workflow-Automatisierungsfunktionen, die hier wirklich wichtig sind, sind spezifisch: Der AI-Agent-Node umhüllt LangChain ohne den Boilerplate, Memory-Sub-Nodes verwalten den Gesprächsstatus, der Queue-Modus mit Redis ermöglicht die Skalierung von Workers über Instanzen hinweg, und jeder Workflow ist als JSON versionierbar. Allein das letzte zahlt den Entwicklungsaufwand zurück, wenn Sie prüfen müssen, was wann geändert wurde.mode with Redis lets you scale workers across instances, and every workflow is version-controllable as JSON. That last one alone pays back the build effort when you need to audit what changed and when.

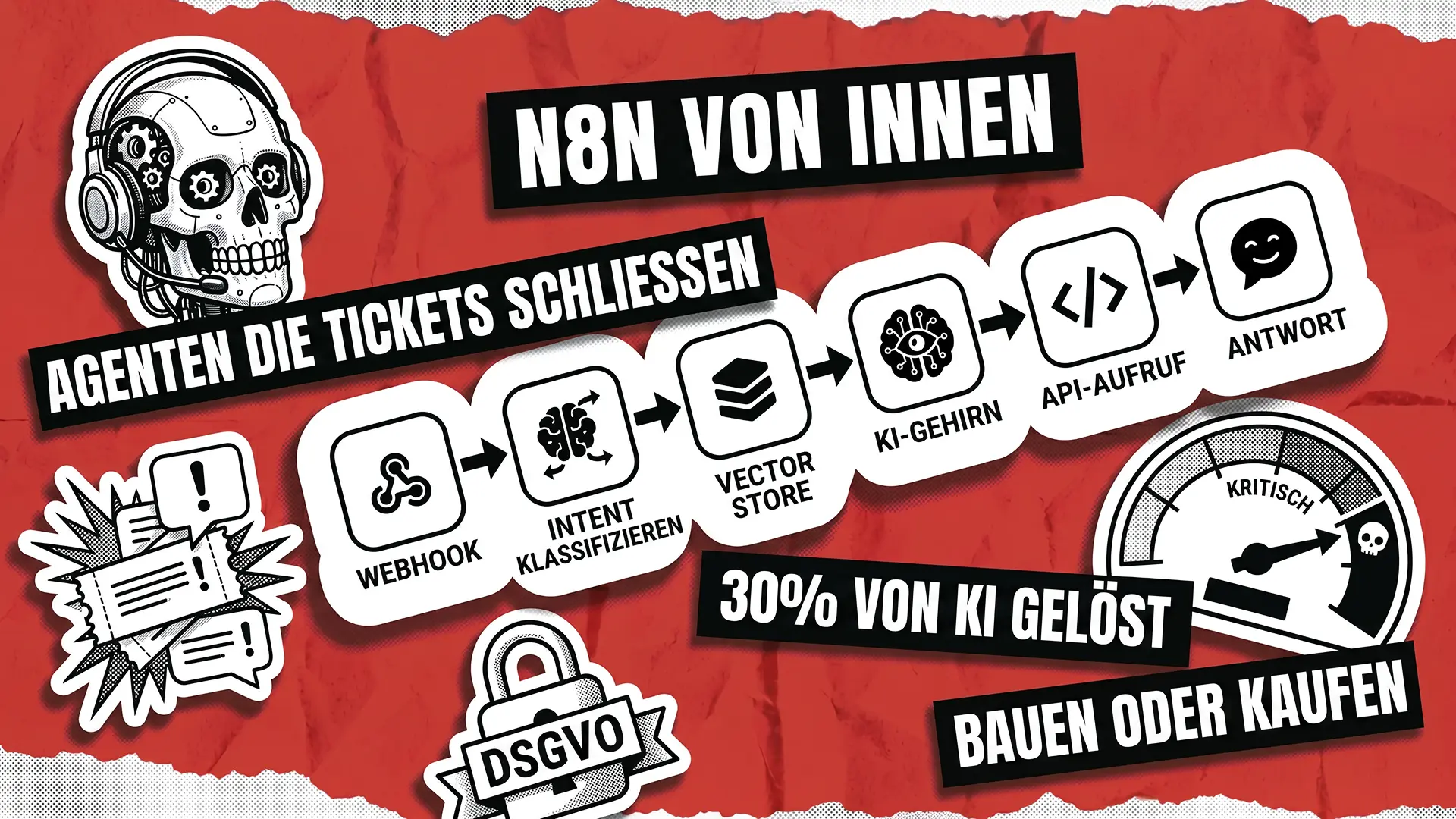
Die Architektur eines KI-Kundensupport-Agenten in n8n
Ein funktionierender Support-Agent ist kein einzelner Workflow. Es ist eine Pipeline aus acht Schichten, jede erledigt eine Aufgabe, jede ist austauschbar. Wenn Sie die Schichtung richtig hinbekommen, können Sie das LLM, den Vektorspeicher oder das Ticketing-System ersetzen, ohne alles neu schreiben zu müssen.ctor store, or the ticketing system without rewriting the whole thing.
Hier ist der Stack, von oben nach unten:
- Eingang. Webhook, E-Mail-Trigger, Chat-Widget oder Helpdesk-API. Diese Schicht akzeptiert rohe Kundeneingaben aus jedem Kanal.
- Normalisierung. Ordnen Sie jeden eingehenden Payload einem Schema zu: Kunden-ID, Kanal, Locale, Nachricht, Priorität. Nachgelagerte Nodes sollten sich nie darum kümmern müssen, woher die Nachricht kam.from.
- Absichtsklassifizierung. Ein kleines, schnelles Modell (gpt-4o-mini funktioniert gut) leitet die Nachricht zum richtigen Sub-Workflow. Abrechnungsfragen gehen in eine Richtung, technische Probleme in eine andere, Churn-Signale in eine dritte.urn signals a third.
- Kontext-Abruf. RAG gegen Ihre Wissensdatenbank. Holen Sie die drei bis fünf relevantesten Chunks mit Quellenangaben.
- Schlussfolgern. Der AI-Agent-Node kombiniert System-Prompt, Memory, abgerufenen Kontext und Tools. Das ist das Gehirn.
- Aktionsausführung. Autorisierte, prüfbare Tool-Aufrufe: Ein Ticket aktualisieren, eine Bestellung erstatten, einen Rückruf planen. Jede Aktion ist ihr eigener Sub-Workflow, kein freiformiger API-Aufruf aus einem Prompt.l from a prompt.
- Antwortzusammenstellung. Marken-Voice-Prüfung, Confidence-Scoring, Leitplanken.
- Beobachtbarkeit. Protokollieren Sie Eingaben, Tokens, Tool-Aufrufe, abgerufenen Kontext und Ergebnisse. Was nicht protokolliert wird, kann nicht debuggt werden.
Die Designregel ist einfach. Jede Schicht hat eine Verantwortung, und jede Schicht kann isoliert getestet werden. Das Überspringen dieser Struktur ist der Weg, wie versteckte Kosten schlechter KI-Integration sich still akkumulieren, bevor sie in der Produktion explodieren, und es ist der mit Abstand häufigste Grund, warum Teams für KI-Entwicklung zweimal bezahlen.
Drei Architekturentscheidungen, die Ihren Support-Agenten entscheiden
Die meisten Kundensupport-Agenten scheitern in der Produktion wegen drei Entscheidungen, die während der Prototypphase zu schnell getroffen wurden. So machen Sie jede richtig.
Memory: Welcher Typ und warum
n8n bietet Ihnen drei Memory-Optionen, und diese sind nicht austauschbar. Simple Memory lebt im Workflow-Ausführungskontext, was bedeutet, dass es verschwindet, wenn der Workflow neu startet. Das ist für eine Demo in Ordnung. Es ist eine Katastrophe mitten in einem Gespräch mit einem frustrierten Kunden in der siebten Minute eines Checkout-Problems.the workflow restarts. That is fine for a demo. It is a disaster mid-conversation with a frustrated customer on minute seven of a checkout issue.
Ihre echten Optionen sind zwei. Postgres Chat Memory bleibt über Neustarts hinweg bestehen, fügt pro Aufruf etwa 40 ms Latenz hinzu und verarbeitet rund 50 gleichzeitige Sitzungen ohne Probleme. Es ist der richtige Standard für die meisten B2B-Support-Workloads. Redis Chat Memory ist das, zu dem Sie greifen, sobald Sie 50 gleichzeitige Sitzungen überschreiten oder n8n im Queue-Modus auf mehreren Instanzen betreiben, mit unter 10 ms Abrufzeit und ohne Blockierung.sions without complaints. It is the right default for most B2B support workloads. Redis Chat Memory is what you reach for once you cross 50 concurrent sessions or move to multi-instance n8n in queue mode, with sub-10 ms retrieval and no blocking.
Eine kleine Regel, die später viel Schmerz spart: Die Sitzungs-ID sollte immer die Kunden-ID sein, nie die Ausführungs-ID. Verknüpfen Sie das Memory damit, wer spricht, nicht damit, welcher Run ausgelöst wurde. So behalten Sie den Kontext über Kanäle hinweg, wenn derselbe Kunde von Chat zu E-Mail wechselt.to which run is fired. This is how you keep context across channels when the same customer switches from chat to email.
Retrieval: Die Antworten verankern
Retrieval ist das, was ein intelligentes Kundendienst-System ehrlich hält. Ohne Verankerung erfindet Ihr Agent Dinge mit voller Zuversicht. Mit Verankerung zitiert er Ihre Dokumente.
Was in der Produktion funktioniert, lässt sich auf vier Praktiken reduzieren:
- Wissensdatenbank-Dokumente in 500-Zeichen-Chunks mit 50-Zeichen-Überlappung aufteilen, kürzer für FAQs und länger für Richtliniendokumente.
- Embeddings in Pinecone, Qdrant oder Supabase pgvector speichern – alle lassen sich sauber in n8n integrieren.
- Mit jeder Antwort Quellenangaben zurückgeben, denn keine Quellenangabe bedeutet keine Antwort.
- Die häufigsten Fragen cachen, weil sich Tier-1-Tickets um wiederkehrende Anfragen häufen und Sie für denselben Inhalt nicht zweimal für einen LLM-Aufruf bezahlen sollten.tent.
Jedes Detail ist hier wichtig, weshalb RAG-Best-Practices eine eigene Teildisziplin im KI-Engineering sind.
Tools: Was der Agent wirklich tun kann
Ein Support-Agent ohne Tools ist ein Chatbot. Ein Support-Agent mit Tools ist ein System, das Tickets lösen kann. Das ist der Kern der Kundendienst-Automatisierung und das, was n8n-KI-Agenten, die Anfragen tatsächlich abschließen, von Bots trennt, die nur Lärm erzeugen.
Tools als explizite Sub-Workflows aufbauen, einen pro Aktion:
- Bestellstatus abfragen
- Rücksendeetikett erstellen
- Erstattung unterhalb eines Schwellenwerts ausstellen
- Rückruf planen
Zwei Regeln halten das sicher. Erstens: Eingaben innerhalb des Tools validieren, nicht innerhalb des Prompts. LLMs werden versuchen, Unsinn zu übergeben, wenn Sie es zulassen. Zweitens: Jede Aktion mit hoher Auswirkung hinter einem menschlichen Genehmigungsschritt absichern: Erstattungen über 100 $, Kontolöschung, Richtlinienausnahmen. Jeden Tool-Aufruf mit Kunden-ID, Eingabe, Ausgabe und Zeitstempel protokollieren, damit Sie einen Nachweis haben, wenn jemand fragt, was passiert ist.every high-impact action behind a human approval step: refunds above $100, account deletion, policy exceptions. Log every tool call with customer ID, input, output, and timestamp, so you have a trail when someone asks what happened.
Was bricht: Fehlermodi aus echten Deployments
Jeder Artikel zu diesem Thema hört beim Idealfall auf. Genau dort beginnt aber der nützliche Teil. Eine Gartner-Umfrage unter 321 Kundendienst-Führungskräften, die im Oktober 2025 durchgeführt wurde, ergab, dass 91 % unter Druck des Managements stehen, KI einzuführen. Lieferdruck erzeugt selten saubere Architektur, weshalb dieselben Fehlermuster in allen Deployments auftauchen. Hier sind die spezifischen Weisen, auf die es in der Praxis bricht.ean architecture, which is why the same failure patterns show up across deployments. Here are the specific ways it breaks in practice.
- Tool-Aufruf-Schleifen. Der Agent ruft immer wieder dieselbe Abfrage auf, weil die Antwort „nicht gefunden” lautet. Beheben Sie dies mit einem Schleifenlimit, einem Timeout und einer eleganten Übergabe an einen Menschen.ff.
- Kontextfenster-Erschöpfung. Ein langes Gespräch überschreitet das Token-Budget und der Agent vergisst, was vor fünf Runden vereinbart wurde. Verwenden Sie Sliding-Window-Memory und fassen Sie ältere Runden in einem einzigen Kontextblock zusammen.urns into a single context block.
- Retrieval-Drift. Ihre Richtlinie hat sich im Januar geändert, aber die Vektor-DB wurde zuletzt im Oktober neu indexiert. Der Agent zitiert zuversichtlich die alte Richtlinie. Beheben Sie das mit geplanter Ingestion, Versions-Tags auf Chunks und einer wöchentlichen Diff-Prüfung.stion, version tags on chunks, and a weekly diff check.
- Rate-Limit-Kaskaden. Traffic-Spitzen, Ihr LLM-Anbieter drosselt, Kunden warten, die Warteschlange wächst, mehr Kunden versuchen es erneut, die Warteschlange wächst weiter. Richten Sie jitterierte Wiederholungsversuche und einen Fallback auf ein kleineres Modell ein.fallback to a smaller model.
- PII in Protokollen. Ihre Ausführungshistorie enthält nun dauerhaft Kreditkartennummern und Privatadressen. Beim Eingang schwärzen, nicht beim Ausgang. Der Rohwert sollte das Protokoll nie berühren.h the log.
- Prompt-Drift. Jemand ändert den System-Prompt an einem Freitag, und die Qualität sinkt das ganze Wochenende, bevor es jemand bemerkt. Prompts in Git versionieren und bei jeder Änderung eine Zehn-Fall-Regressionssuite durchführen.on suite on every change.
Jeder Punkt auf dieser Liste ist früher erkennbar, als Teams erwarten, sofern rigorose Qualitätssicherung von Anfang an in den Workflow eingebaut wird, statt beim Start nachgerüstet zu werden. Dieselbe Strenge gilt während der gesamten Lebensdauer des Systems, weshalb dauerhaftesurable Software-Wartung im KI-Zeitalter sehr anders aussieht als das Bekämpfen von Bränden in einem Legacy-Monolithen.
Die Metriken, die Ihnen zeigen, dass es funktioniert
Metriken sind wichtig, weil Ihr CFO fragen wird. Hier ist, was Sie beobachten sollten und wie gut im Jahr 2026 aussieht:
- Abwehrquote. Prozentsatz der Tickets, die ohne einen Menschen gelöst werden. Salesforces Daten von 2025 setzt die aktuelle Branchenbasis bei 30 % der durch KI gelösten Fälle, wobei Service-Führungskräfte bis 2027 50 % und eine durchschnittliche Reduzierung der Service-Kosten und -Lösungszeiten um 20 % erwarten. costs and resolution times.
- Erste Antwortzeit. Hier übertrifft KI Menschen am sichtbarsten und bewegt sich oft von Stunden auf Sekunden, sobald die Eingangs- und Absichtsschichten abgestimmt sind.
- Bearbeitungsabstand. Wenn ein menschlicher Agent eine Antwortentwurf übernimmt, wie viel ändert er? Weniger ist besser, und das ist Ihr stilles Qualitätssignal.
- Kosten pro Lösung. KI-bearbeitete Tier-1-Tickets kosten einen kleinen Bruchteil der menschlich bearbeiteten, weshalb der ROI-Fall in der Regel standhält, noch bevor Sie Abwehrgewinne einrechnen.ins.
- CSAT bei KI-bearbeiteten Tickets. Laut dem Zendesk CX Trends 2026 Report sagen 85 % der CX-Führungskräfte, dass Kunden eine Marke wegen eines einzigen ungelösten Problems verlassen werden – Ihre Basis darf also nicht sinken. Unternehmen, die Tier-1-KI-Abwehr mit sauberen Daten einsetzen, sehen CSAT typischerweise innerhalb von 90 Tagen steigen, nicht sinken.ction with clean data typically see CSAT improve, not decline, within 90 days.
Richten Sie eine wöchentliche Review-Schleife für alle fünf ein: Protokollüberprüfung, Prompt-Tuning, Wissensdatenbank-Auffrischung. Diese Schleife ist der Unterschied zwischen einem Pilot, der stagniert, und einem System, das sich Monat für Monat verbessert. system that improves month over month.
Vom Prototyp zur Produktion
Compliance ist 2026 kein Nachgedanke. Googles offizielle Leitlinien zu KI-generierten Inhalten setzen den Standard für alles, was Ihr Agent produziert: Ausgabe, die Kunden erreicht, in der Suche rangiert oder Entscheidungen beeinflusst, muss nützlich, zuverlässig und menschenzentriert sein – kein automatisch generierter Füllstoff. Derselbe Maßstab gilt dafür, was Ihr Support-Agent einem zahlenden Kunden um 2 Uhr morgens sagt.es decisions has to be useful, reliable, and people-first, not auto-generated filler. The same bar applies to what your support agent says to a paying customer at 2 a.m.
Überprüfen Sie vor dem Ausliefern diese drei Dinge:
- Der Agent verweigert, was er verweigern sollte
- Er eskaliert zu einem Menschen, wann immer die Konfidenz unter Ihren Schwellenwert fällt
- Er antwortet bei Faktenfragen nie ohne Quellenangabe
Das ist, was einen Chatbot, der Sie blamiert, von einem KI-Kundensupport-Agenten trennt, der tatsächlich Vertrauen verdient. Kombinieren Sie das mit einem ordentlichen digitalen Transformations-Ansatz, und Sie haben ein System, das das Unternehmen voranbringt statt es zu dekorieren.
Fazit
Ein KI-Support-Agent in n8n ist ein echtes System, kein Wochenendprojekt. Bauen Sie es in Schichten, treffen Sie die drei schwierigen Entscheidungen zu Memory, Retrieval und Tools mit offenen Augen, planen Sie für die sechs Fehlermodi, bevor sie für Sie planen, und messen Sie die fünf Zahlen jede Woche.with eyes open, plan for the six failure modes before they plan for you, and measure the five numbers every week.
Wir bauen und prüfen seit 2005 Produktionssysteme in Nordamerika, Europa, Australien und Neuseeland. Wenn Sie einen Entwickler möchten, der Ihren Agenten stress-testet, bevor er echte Kunden trifft, stress-test your agent before it meets real customers, kontaktieren Sie uns und wir richten eine dreißigminütige Architekturüberprüfung ein. Keine Folien, nur ehrliches Feedback.
Erfahren Sie, wie wir MyJiraBot — einen Telegram-Automatisierungsbot, der jetzt Workflows für 50+ Unternehmen weltweit abwickelt.



