
Webcrawler sind Programme zum massenhaften Herunterladen und Verarbeiten von Internetinhalten. Sie werden oft auch „Spider“, „Roboter“ oder einfach „Bots“ genannt. Im Grunde tut ein Crawler dasselbe wie ein gewöhnlicher Webbrowser: Er sendet HTTP-Anfragen an Server und ruft Inhalte aus deren Antworten ab. Was danach passiert, ist jedoch eine andere Geschichte: Während ein Browser diese Inhalte verarbeitet und für die Benutzer darstellt, analysiert ein Crawler sie und extrahiert Daten, die bestimmte Kriterien erfüllen. Dazu gehört auch das Abrufen von Links zu anderen Seiten und das Crawlen dieser Seiten. Seite abrufen, Seite analysieren, Daten verarbeiten, Links zu anderen Seiten finden, spülen, waschen, wiederholen: Das ist ein einfacher Crawler in Kurzform.
Was ist ein Web Crawler?
Webcrawler sind Programme zum massenhaften Herunterladen und Verarbeiten von Internetinhalten. Sie werden oft auch „Spider“, „Roboter“ oder einfach „Bots“ genannt. Im Grunde tut ein Crawler dasselbe wie ein gewöhnlicher Webbrowser: Er sendet HTTP-Anfragen an Server und ruft Inhalte aus deren Antworten ab. Was danach passiert, ist jedoch eine andere Geschichte: Während ein Browser diese Inhalte verarbeitet und für die Benutzer darstellt, analysiert ein Crawler sie und extrahiert Daten, die bestimmte Kriterien erfüllen. Dazu gehört auch das Abrufen von Links zu anderen Seiten und das Crawlen dieser Seiten. Seite abrufen, Seite analysieren, Daten verarbeiten, Links zu anderen Seiten finden, spülen, waschen, wiederholen: Das ist ein einfacher Crawler in Kurzform.
Crawler in der realen Welt tun jedoch viel mehr als das. Sie werden an vielen verschiedenen Stellen und für viele verschiedene Zwecke eingesetzt. So dienen Crawler beispielsweise als Kernkomponenten von Suchmaschinen wie Google, Yahoo, Bing und anderen. Diese Heerscharen von Crawlern suchen, finden, analysieren und indexieren ständig Inhalte aus dem Internet. Dank ihrer unermüdlichen Arbeit können Sie sich darauf verlassen, dass Sie Inhalte finden, die Ihren Interessen entsprechen, indem Sie einfach Ihre Anfrage in ein kleines Suchfeld eingeben.
Eine weitere Aufgabe der Crawler ist die Archivierung von Websites. Fortgeschrittene Crawler können regelmäßig vollständige Kopien des Inhalts einer Website erstellen und diese in einem Repository speichern, wo sie abgerufen, angesehen und miteinander verglichen werden können, so dass eine Zeitleiste der Änderungen im Laufe von Tagen, Monaten oder sogar Jahren entsteht. Die auf diese Weise gespeicherten Inhalte werden digital signiert, so dass sie sogar vor Gericht als Beweismittel verwendet werden können.
Ein weiterer beliebter Einsatzbereich für Crawler ist das Data Mining, also das Extrahieren von Informationen aus Webinhalten und deren Umwandlung in ein verständliches Format zur weiteren Verwendung. Ein gutes Beispiel hierfür ist der Google AdSense-Bot, der nach Seiten mit AdSense-Werbung sucht und diese auf Verstöße gegen die Richtlinien überprüft.
Webcrawler werden auch häufig zu Überwachungszwecken eingesetzt. Crawler können automatisch überprüfen, ob Websites und Webanwendungen ordnungsgemäß funktionieren, und so sicherstellen, dass Ausfallzeiten minimal sind und etwaige Fehler schnell behoben werden.
Nicht zuletzt werden Webcrawler auch zum Scraping eingesetzt. Die meisten Unternehmensportale bieten keine einfache Möglichkeit, die von ihnen bereitgestellten Inhalte in ein brauchbares Format zu exportieren, und diejenigen, die dies tun, bieten in der Regel umständliche Schnittstellen und langsame APIs. Solche Hindernisse schmälern jedoch nicht die Nachfrage nach diesen Daten, und Webcrawler eignen sich perfekt für die Aufgabe, sie zu extrahieren. Spezialisierte Crawler, so genannte „Scraper“, wurden entwickelt, um die Anti-Crawling-Maßnahmen solcher Portale zu umgehen, indem sie ein normales Surfverhalten nachahmen und ihnen vorgaukeln, dass ein Mensch die Website besucht und nicht ein Bot.
Aus diesen Beispielen wird deutlich, dass Crawler ständig damit beschäftigt sind, das Internet zu durchforsten, aber wir halten es dennoch für wichtig, das schiere Ausmaß der Arbeit, die sie leisten können, mit einigen Zahlen zu illustrieren:
- Ein Crawler namens IRLbot lief zwei Monate lang auf einem Supercomputer. Er sammelte in diesem Zeitraum mehr als 6,4 Milliarden Seiten, arbeitete mit einer durchschnittlichen Geschwindigkeit von etwa 1.000 Seiten pro Sekunde und extrahierte über 30 Milliarden URLs.
- Seit 1995 haben die Crawler von Google und Yahoo zusammen über 1 Billion Seiten indiziert.
Herausforderungen des Web Crawling
Crawler sind sehr gefragt, und sie können eine lukrative Investition sein. Aber es gibt auch eine Reihe von Vorbehalten hinsichtlich ihres Betriebs und ihrer Instandhaltung zu beachten:
Technische Herausforderungen auf höchster Ebene
- Crawler im industriellen Maßstab sind verteilte Systeme mit hoher Last und enormen Anforderungen an Speicherplatz und Bandbreite. Für den Betrieb eines solchen Systems benötigen Sie eine Flotte von High-End-Servern und ein qualifiziertes Team, das es implementiert und wartet. Je komplexer Ihr Crawler ist, desto höher sind die Kosten für die Infrastruktur und den Support.
- Web-Crawling ist ein Wettbewerbsfeld – nicht nur zwischen Crawlern und Anti-Crawling-Maßnahmen, sondern auch zwischen verschiedenen Crawlern in denselben Arbeitsbereichen. Ein unbedarfter Crawler vergeudet wertvolle Taktzyklen und Bandbreite, die andere, intelligentere Crawler für die Verarbeitung relevanterer Inhalte verwenden. Ohne eine entsprechende Optimierung könnten Sie sich genauso gut die Mühe machen, überhaupt keinen Crawler einzusetzen.
- Apropos naives Crawling: Ein wahlloses Vorgehen beim Sammeln von Inhalten kann schwerwiegende Folgen haben, wenn Ihr Crawler urheberrechtlich geschütztes Material aufspürt. Wenn Sie keine Maßnahmen ergreifen, um dies zu verhindern, könnten Sie mit rechtlichen Schritten konfrontiert werden, wenn Ihr Crawler das Urheberrecht von jemandem verletzt.
Angesichts dieser Faktoren ist es klar, dass ein einfacher Crawler für eine reale Anwendung nicht ausreicht. Die Entwicklung eines effektiven Crawlers erfordert Mühe und Überlegung und beginnt mit der Berücksichtigung der folgenden Herausforderungen:
Herausforderungen bei der Umsetzung
Umfang der Aufgabe. Das Internet ist ein riesiger Ort, und es wird von Sekunde zu Sekunde größer. Um mit den neuesten (oder sogar relativ neuesten) Daten Schritt halten zu können, muss Ihr Crawler schnell und effizient sein. Bei all den verschiedenen Aufgaben, die ein effektiver Crawler bewältigen muss, kann das ganz schön knifflig sein!
Verarbeitung von Inhalten. Im Idealfall verarbeitet Ihr Crawler jede Seite, die er braucht, und überspringt jede Seite, die er nicht braucht. Klingt nach einer einfachen Anforderung, nicht wahr? Leider kann es allzu leicht passieren, dass ein Crawler riesige Mengen irrelevanter Inhalte verschluckt oder unzählige wertvolle Daten ignoriert. Einer der entscheidenden Unterschiede zwischen einem intelligenten, schnellen Crawler und einem langsamen, ineffizienten Crawler ist die Art und Weise, wie er die zu sammelnden Daten auswählt.
Pflege der Ressourcen, die gecrawlt werden. Wenn Sie die gesamte Macht Ihres Crawlers gegen jede Website einsetzen, auf die Sie stoßen, ist das ein guter Weg, um versehentlich ein unverdientes Opfer zu DDoS zu machen – und sich möglicherweise einer Klage auszusetzen. Seien Sie keine Bedrohung für das Internet: Sie müssen sicherstellen, dass Ihr Crawler in der Lage ist, sich selbst auf der Grundlage des maximalen Durchsatzes des Servers, auf den er zuzugreifen versucht, zu begrenzen.
Probleme mit dynamischen Inhalten. Wir haben bereits erwähnt, dass Browser und Crawler sehr unterschiedlich mit den Inhalten umgehen, die sie von Servern abrufen: Browser verarbeiten und rendern, während Crawler analysieren und extrahieren. Dies kann ein Hindernis darstellen, wenn eine Website Inhalte dynamisch generiert, z. B. mit JavaScript. Stellen Sie sich ein Theaterstück vor, bei dem die Schauspieler die Regieanweisungen vorlesen, anstatt sie tatsächlich auszuführen: Das ist ein typisches Crawler-Verhalten, wenn es um Skripte geht. Es ist immer noch möglich, dass ein Crawler Inhalte und Links erfasst, die auf diese Weise generiert wurden, aber seien Sie gewarnt, dass dies einen Preis in Bezug auf die Leistung hat.
Probleme mit Multimedia-Inhalten. Websites, die Flash, Silverlight und HTML5 verwenden, stellen ein ganz eigenes Problem dar: Es gibt einfach keine Möglichkeit für einen Crawler, Daten aus einem Plugin oder einem Canvas-Objekt zu analysieren und zu extrahieren. Was Sie tun können, ist, Inhalte indirekt zu erfassen: zum Beispiel, indem Sie Anfragen verfolgen, die von einem Flash-Container aus gemacht werden. Jede Art von Multimedia muss separat behandelt werden, und auch dies hat Auswirkungen auf die Gesamtleistung Ihres Crawlers.
Crawling-Probleme bei sozialen Medien. Soziale Netzwerke – Facebook, Twitter, Tumblr, Google+, Instagram, etc. – sind eine nie versiegende Quelle nützlicher, wertvoller Daten. Leider stellen sie für Crawler jedes einzelne der oben beschriebenen Hindernisse auf einmal dar – und noch einige mehr! Es mag verlockend sein, sich einfach über die von den sozialen Netzwerken selbst zur Verfügung gestellten Mittel und ihre Client-APIs einen Weg durch das Durcheinander zu bahnen, aber diese sind sowohl in Bezug auf die Art der Daten, auf die Sie zugreifen können, als auch in Bezug auf die Effizienz des Zugriffs begrenzt – Sie werden mit Sicherheit nicht in der Lage sein, einen vollständigen Schnappschuss zu erhalten.
Einen Crawler zu bekommen, der die Investition wert ist, klingt bereits wie ein Hindernislauf, aber wir stehen erst am Anfang. Es gibt noch eine weitere Aufgabe, die das alles wie ein Kinderspiel erscheinen lässt und die ein eigenes Kapitel verdient: das Crawlen geschützter Bereiche.
Herausforderungen beim Crawling geschützter Bereiche
Das Crawlen geschützter Bereiche ist eine der schwierigsten Aufgaben beim Crawlen von Webseiten. Es gibt zahllose verschiedene Authentifizierungssysteme, und Ihr Crawler muss jedes einzelne davon unterstützen – andernfalls wird er auf riesige Mengen von Inhalten einfach nicht zugreifen können. Viele unserer Kunden haben uns sogar gebeten, das Crawling geschützter Bereiche als spezielle Funktion zu implementieren, aber das ist leichter gesagt als getan. Im Folgenden finden Sie eine Übersicht über die Herausforderungen, die das Crawling geschützter Bereiche mit sich bringt:
Bedenken bezüglich des Verhaltens von Kriechern
Die erste Regel beim Crawlen in geschützten Bereichen ist so einfach wie wichtig: Gehen Sie vorsichtig vor. Erinnern Sie sich an den Satz „Seien Sie keine Bedrohung für das Internet“, den wir vorhin gesagt haben? Jedem Link zu folgen und jede Aktion durchzuführen, auf die Sie Zugriff haben, ist ein todsicheres Rezept für zerstörte Daten, verärgerte Nutzer und rechtliche Schritte gegen Sie und Ihren unverantwortlichen Crawler. Sie müssen dafür sorgen, dass Ihr Crawler:
- Löscht nichts, was Benutzer löschen dürfen (auch nicht das Benutzerkonto selbst!)
- Versucht nicht, Benutzerdaten zu ändern (Benutzernamen, Passwörter usw.)
- Führt keine Aktionen zur Inhaltsmoderation durch (z. B. das Melden von Inhalten anderer Nutzer)
- Keine Veröffentlichung von Inhalten
- keine Benutzerbenachrichtigungen abweisen
- Und so weiter!
Die Kurzfassung ist, dass Sie einen Weg finden müssen, um sicherzustellen, dass Ihr Crawler sich „schreibgeschützt“ verhält. Das ist schwieriger als es klingt! Stellen Sie sich vor, Sie lassen ein Kleinkind auf die wertvollen Daten von jemandem los, das keine Ahnung hat, was es anfassen darf und was nicht, was sein neugieriges Stochern und Rütteln aushält, ohne kaputt zu gehen – und wenn es dabei ist, etwas Wichtiges zu ruinieren, sind die Chancen groß, dass Sie es nicht rechtzeitig aufhalten können. So sieht das naive Krabbeln in geschützten Bereichen aus, und es bedarf einer ausgeklügelten Programmierung, um sicherzustellen, dass Ihr Krabbler ein Gefühl dafür hat, was er gefahrlos berühren kann und was nicht.
Aber genug von möglichen Crawler-Katastrophen – wie bekommt man ihn überhaupt in geschützte Bereiche? Wir werden uns einige gängige Autorisierungsmechanismen ansehen, um Ihnen ein Gefühl für das Ausmaß des Problems zu vermitteln:
Authentifizierungsmechanismen
HTTP-Basisauthentifizierung (BA). Dies ist der einfachste Weg, Zugangskontrollen für Webressourcen durchzusetzen: keine Cookies, keine Sitzungskennungen, keine Anmeldeseiten, nur Standard-HTTP-Header. Nahezu jede Netzbibliothek, die es gibt, unterstützt es von Haus aus, so dass es trivial ist, es in Ihrem Crawler zu unterstützen, aber der Preis für diese Einfachheit ist die fehlende Sicherheit: BA tut nichts, um übertragene Anmeldeinformationen zu schützen, außer sie in Base64 zu kodieren, was nur einen Schritt davon entfernt ist, sie einfach im Klartext zu übertragen. Aus diesem Grund sollte BA – wenn überhaupt – über HTTPS verwendet werden, um ein gewisses Maß an Sicherheit zu gewährleisten.
Zertifikatsbasierte Authentifizierung. Während das Wort „Zertifikat“ an etwas denken lässt, das man sich an die Wand hängt oder anstelle von Bargeld verschenkt, bezieht es sich hier auf eine Implementierung der Authentifizierung mit öffentlichem Schlüssel. Ein Zertifikat ist ein digitales Dokument, das den Besitz eines öffentlichen Schlüssels nachweist: Wenn das Zertifikat eine gültige Signatur von einer vertrauenswürdigen Stelle hat, weiß der Browser, dass es sicher ist, diesen öffentlichen Schlüssel für eine sichere Kommunikation zu verwenden. Wie die Basisauthentifizierung ist auch die zertifikatsbasierte Authentifizierung in Netzbibliotheken so weit verbreitet, dass Sie keine Probleme haben sollten, sie in Ihrem Crawler zu unterstützen, aber Sie müssen für jeden geschützten Bereich, den Sie crawlen wollen, gültige Zertifikate erhalten.
OAuth. OAuth ist ein offener Autorisierungsstandard, der es Benutzern ermöglicht, Websites und Anwendungen sicheren Zugriff auf ihre Daten zu gewähren, ohne ihre Anmeldeinformationen weitergeben zu müssen. Wenn Sie schon einmal Ihre Microsoft-, Google-, Twitter- oder Facebook-Anmeldung verwendet haben, um sich ohne Passwort bei einer Website eines Drittanbieters anzumelden, haben Sie OAuth in freier Wildbahn kennengelernt. OAuth-Unterstützung von Grund auf zu implementieren kann schwierig sein, daher empfehlen wir, die Vorteile bestehender Bibliotheken wie Scribe für Java zu nutzen.
OpenID. OpenID ist ein offener Authentifizierungsstandard, der es Benutzern ermöglicht, sich über einen Drittanbieterdienst bei Websites anzumelden. Im Gegensatz zu OAuth, das sich nur mit der Autorisierung befasst (d. h. mit der Gewährung des Zugriffs auf Daten zwischen Websites), bietet OpenID ein Mittel, mit dem sich Benutzer bei mehreren Websites mit nur einem einzigen Satz von Anmeldeinformationen authentifizieren können. OpenID wird von vielen bestehenden Bibliotheken unterstützt, was die Implementierung erleichtert.
Und nun kommen wir zur häufigsten Art der Authentifizierung im Web: die formularbasierte Authentifizierung. Sie bedarf praktisch keiner Einführung: Der Benutzer erhält eine Reihe von Feldern zur Eingabe seiner Anmeldedaten (in der Regel ein Benutzername und ein Passwort), die dann vom Server überprüft werden. Schauen wir uns einen typischen formularbasierten Authentifizierungsprozess Schritt für Schritt an:
- Ein unbefugter Benutzer versucht, auf eine sichere Seite zuzugreifen
- Der Server antwortet mit einer Seite, die ein Authentifizierungsformular enthält
- Der Benutzer gibt seine Anmeldedaten in das Formular ein und übermittelt sie
- Der Server prüft die übermittelten Anmeldeinformationen
- Wenn die Anmeldedaten gültig sind, erhält der Benutzer ein Authentifizierungs-Token/Cookie/etc. und wird zur sicheren Seite weitergeleitet
Werfen wir nun einen Blick auf ein typisches Authentifizierungsformular:
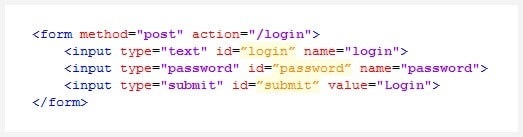
Nicht gerade einschüchternd, oder? Auf den ersten Blick scheint es trivial zu sein, die Authentifizierung über diese oder eine andere Form in Ihren Crawler zu integrieren. Es wäre so einfach wie:
- Abrufen und Parsen der Authentifizierungsseite
- Finden Sie das Authentifizierungsformular und extrahieren Sie den Endpunkt und die Parameter
- Erzeugen einer POST-Anfrage mit den aus dem Formular extrahierten Parametern und unseren Anmeldedaten
- Ausführen der Anfrage und Empfang des Authentifizierungs-Tokens/Cookies/etc. vom Server
- Krabbeln Sie los!
Wenn es nur wirklich so einfach wäre! In der Praxis werden Sie mit Szenarien wie diesen konfrontiert:
- Das Authentifizierungsformular befindet sich in einem iframe und funktioniert nur auf der Anmeldeseite
- Das Authentifizierungsformular wird durch JavaScript generiert
- Die Website verwendet einen Authentifizierungsserver eines Drittanbieters
- Der Authentifizierungsendpunkt und/oder die Parameter werden dynamisch erstellt
- Die Domänenautorität des Zielservers stimmt nicht mit der Authentifizierungsdomänenautorität überein
- Die Anfrage erfordert eine dynamische digitale Beschilderung
Ihr Crawler könnte am Ende mit einer beliebigen Kombination dieser Komplikationen konfrontiert werden – wie z. B. mit einem JavaScript-generierten Authentifizierungsformular von einem Drittanbieter-Server mit dynamisch generierten Parametern, das eine digitale Signatur erfordert. Das ist übrigens nicht nur ein hypothetisches Worst-Case-Szenario: So haben die internen Unternehmensportale bei McDonald’s früher funktioniert!
Eine weitere potenzielle Komplikation bei der Authentifizierung sind „Umleitungsstürme“: Sie werden zwischen mehreren Authentifizierungsservern hin- und hergeschoben, von denen jeder seine eigenen Authentifizierungs-Cookies setzt. Für einen Browser ist das kein Problem, aber für einen Crawler müssen Sie sicherstellen, dass jede Seite korrekt ausgewertet wird, damit Sie alle für die Authentifizierung erforderlichen Cookies und Header erhalten. Um ein weiteres Beispiel aus der Praxis zu nennen: Die Unternehmensportale von RJR Tobacco haben die Authentifizierung auf diese Weise gehandhabt!
Dies sind nur einige der Herausforderungen, mit denen Sie beim Crawlen geschützter Bereiche konfrontiert werden. Es ist einfach keine Option, Lösungen für jeden einzelnen Fall zu programmieren: Es gibt einfach zu viele verschiedene Szenarien, die es zu bewältigen gilt. Was Sie jedoch tun können, ist, eine „Einheitslösung“ zu implementieren, die an jede Situation angepasst werden kann, mit der eine Website Ihren Crawler konfrontieren könnte. Wir werden im nächsten Kapitel darüber sprechen.
Implementierungsansätze
Wie im vorangegangenen Kapitel erwähnt, ist der beste Weg, die Authentifizierung in einem Crawler zu handhaben, ein „Schweizer Taschenmesser“-Ansatz: Anstatt eine Vielzahl von Tools für die verschiedenen Szenarien zu verwenden, haben Sie ein einziges Tool, das alle Szenarien abdecken kann. Klingt nach einer großen Aufgabe, nicht wahr? Das kann es auch sein – aber es handelt sich um ein gut erprobtes Gebiet, und es gibt zwei bewährte Wege dorthin:
1. Anpassung des Authentifizierungsmechanismus nach Bedarf (d. h. Skripting).
Für diesen Ansatz ist es selbstverständlich, dass Sie Ihrem Crawler eine Art von Skriptunterstützung hinzufügen müssen. Sobald das erledigt ist, erstellen Sie ein Standardskript – eine Reihe von Anweisungen für die Handhabung der grundlegenden Benutzername-Passwort-Anmeldeformulare, die die meisten Websites verwenden. Und wenn Ihr Crawler auf etwas stößt, das Ihr Standardskript nicht bewältigen kann (zusätzliche Hashes, dynamische Parameter, Umleitungsstürme usw.), müssen Sie nur noch ein benutzerdefiniertes Authentifizierungsskript schreiben, das sich darum kümmert. Ganz einfach!
Es gibt nur zwei Probleme mit diesem Ansatz:
- Sie können nicht feststellen, ob Ihr Crawler Probleme bei der Anmeldung hat, es sei denn, jemand meldet das Problem
- Sie müssen Websites ständig auf Änderungen überprüfen, um Ihre Skripte auf dem neuesten Stand zu halten
Hier ist ein weiteres Szenario aus dem wirklichen Leben, um das Problem zu veranschaulichen. Vor einiger Zeit implementierte Redwerk das Crawling von Facebook und Twitter. Anstatt jedoch nur Informationen über die APIs zu sammeln, wurde unser Crawler so eingerichtet, dass er vollständige, funktionale Schnappschüsse erstellt, die man tatsächlich durchsuchen und navigieren kann, als wäre man auf der ursprünglichen Website. Das war nicht die effizienteste und definitiv nicht die einfachste Methode, aber wir haben es mit Hilfe von benutzerdefinierten Authentifizierungsskripten zum Laufen gebracht – und das ganze zwei Monate lang. Facebook und Twitter änderten ihre Authentifizierungssysteme, und wir mussten unsere Authentifizierungsskripte neu schreiben, um sie anzupassen. Seitdem ist es ein ständiges Katz-und-Maus-Spiel: Hin und wieder wird die Authentifizierung geändert, und wir müssen unsere Skripte überarbeiten, damit sie mit dem neuen Setup funktionieren. Auf jeden Fall war die Skripterstellung die beste und wahrscheinlich einzige Möglichkeit, das zu erreichen, was wir erreicht haben, aber sie hat ihren Preis in Form von Wartungsaufwand!
2. Browser-Engine-basierte Dienste
Ein alternativer Ansatz besteht darin, einen Authentifizierungsdienst zu erstellen, der auf einer Browser-Engine oder einem Web-Toolkit wie PhantomJS, CasperJS oder Node.jsbasiert. In Anbetracht all der Probleme, die sich aus den Unterschieden zwischen der Verarbeitung von Websites durch Crawler und Browser ergeben, macht es nur Sinn, eines davon zu lösen, indem man die Lücke zwischen den beiden schließt: Abgesehen von strengen Anti-Crawling-Maßnahmen stellt ein Browser-Engine-basierter Authentifizierungsdienst sicher, dass Websites für Ihren Crawler genauso funktionieren wie für Benutzer. Sogar Flash- und HTML5-Inhalte werden für Ihren Crawler perfekt funktionieren!
Der Prozess ist einfach: Ihr Crawler fragt Ihren Authentifizierungsdienst ab, bevor er versucht, einen geschützten Bereich einer Website zu crawlen, und Ihr Dienst wickelt alle erforderlichen Anmeldevorgänge ab.
Sie können auch einen Mechanismus zur erneuten Authentifizierung einbauen, der es Ihrem Crawler ermöglicht, seine Authentifizierung automatisch zu erneuern, wenn sie aus irgendeinem Grund abläuft. Zu den Funktionen, die Ihr Dienst bieten sollte, gehören:
- Übermittlung von Crawler-Anfragen zur Durchführung der Authentifizierung (in der Regel über eine REST-API)
- Durchführung der Authentifizierung unter Verwendung der vom Crawler erhaltenen Parameter (Anmelde-URL, Anmeldedaten, Timeouts usw.)
- Sammeln und Zurückliefern der relevanten Authentifizierungsergebnisse (Cookies, Header, Token usw.)
- Sicherstellen, dass die Authentifizierungsdaten eindeutig sind und nicht zwischen verschiedenen Aufgaben ausgetauscht werden (Sie wollen doch nicht, dass jemand Ihr Profil crawlt, oder?)
Mit der browserbasierten Authentifizierung brauchen Sie nicht für jede ungewöhnliche Situation eine eigene Lösung (obwohl Sie immer noch Wege finden müssen, um mit den unzähligen Rand- und Eckfällen umzugehen, die es gibt). Ein weiterer Vorteil ist, dass Sie ein Benachrichtigungssystem einrichten können, das Sie darüber informiert, wann – und warum – sich Ihr Crawler nicht bei einer Website anmelden kann.
Und jetzt, wo Sie einen browserbasierten Dienst haben, warum sollten Sie sich auf die Authentifizierung beschränken? Ihr Dienst kann auch andere Dinge tun, die Ihnen das Leben leichter machen: z. B. Serveranfragen verfolgen und Ressourcen extrahieren, so dass es ganz einfach ist, dynamisch generierte Inhalte zu erfassen. Sie können sogar die gesamte Funktionalität Ihres Crawlers auf diese Weise implementieren, aber das ist keine einfache Aufgabe, und je nach Zweck Ihres Crawlers lohnt es sich möglicherweise nicht.
Beide Ansätze haben unter verschiedenen Umständen ihre Vorteile. Lassen Sie sich weder auf das eine noch auf das andere festlegen: Die Loyalität gegenüber einem bestimmten technischen Stack wird Ihnen nicht helfen, Ihre Arbeit zu erledigen.
Zusammenfassung
Wir sind uns bewusst, dass dies nicht das Nonplusultra unter den Anleitungen für Web-Crawler ist: Es steht Ihnen frei, mit allem, was wir zu diesem Thema gesagt haben, nicht einverstanden zu sein. Dennoch basiert dieser Leitfaden auf unseren eigenen Erfahrungen bei der Arbeit mit Crawlern, und unsere Ratschläge beruhen auf Lösungen für Probleme, die wir selbst erlebt haben. Wir hoffen, dass er Ihnen zumindest dabei hilft, einige der Fallstricke zu vermeiden, auf die Neulinge im Bereich Webcrawling häufig stoßen. Crawler sind komplizierte Systeme, aber wenn Sie sie richtig bedienen, können Sie erstaunliche Ergebnisse erzielen.
Über Redwerk
Das Unternehmen Redwerk ist auf die Bereitstellung hochwertiger Softwareentwicklungsdienste für verschiedene Branchen spezialisiert. Eine unserer Stärken ist es, Unternehmen mit Data-Mining- und Web-Crawling-Softwarelösungen zu versorgen, die darauf abzielen, Informationen für strategische Entscheidungen zu sammeln und Geschäftsprozesse zu verbessern. Das Team von Redwerk ist immer bereit, neue Produkte für unsere Kunden zu entwickeln und bestehende zu verbessern.
Automatisierte Web Crawling Projekte, die wir durchgeführt haben
Hören Sie von unserem Kunden
«Redwerk ist ein erfahrener IT-Dienstleister, der sich auf komplexe Anwendungsentwicklung, Qualitätssicherung und Support spezialisiert hat. Ihr Team ist hochqualifiziert, pünktlich und hält in der Regel den Kostenrahmen ein. Sie haben ein kosteneffizientes Bereitstellungsmodell und erfüllen die technischen und geschäftlichen Anforderungen von LinkTiger. Ich habe ihre Dienste vielen Geschäftskollegen empfohlen und sie haben mir dafür gedankt.» — Steve Moskowski, Eigentümer von Linktiger.com
