
Im ersten Teil des Artikels haben wir zwei beliebte Search-as-a-Services kurz vorgestellt: Microsoft (MS) Azure Search und Elasticsearch. In diesem Teil werden wir in der Praxis zeigen, wie man mit einigen häufig verwendeten Funktionen von Azure Search am Beispiel der Suche nach einem Restaurant arbeitet.
Überblick über das Azure-Portal und Erstellen einer Azure-Suchressource
Wir zeigen Ihnen, wie Sie ein kostenloses Azure-Konto erstellen (mit einem kurzen Überblick über das Azure-Portal selbst), wie Sie eine Suchressource erstellen und wie Sie mit diesen arbeiten. MS Azure bietet die Möglichkeit, ein kostenloses Testkonto mit 200 $ Guthaben für 30 Tage, 12 Monate beliebter kostenloser Dienste und natürlich 25+ immer kostenlose Dienste zu erstellen. Sie müssen eine Telefonnummer, eine Kredit- oder Debitkarte und einen MS-Konto-Benutzernamen angeben, um es nutzen zu können. Denken Sie auch daran, dass Sie für die Erstellung eines Kontos etwas Geld auf Ihrer Karte haben müssen, denn es kann sein, dass Ihr Kreditkartenkonto mit einem Dollar belastet wird, der innerhalb von drei bis fünf Tagen entfernt wird. Auf der Seite “Azure Free Account FAQ” können Sie etwas mehr über die angebotenen Dienste und Testkonten lesen.
Nachdem Sie sich auf dem Portal registriert haben, sehen Sie Ihr Dashboard. In der oberen rechten Ecke finden Sie kurze Informationen zu Ihrem Konto (E-Mail und Avatar), mit einem Klick darauf können Sie Ihre Einstellungen, Rechnungsinformationen usw. überprüfen. Um eine neue Suchressource zu erstellen, müssen Sie auf die Option „Ressource erstellen“ im linken Menü klicken, die sich oben in der Liste befindet. Wenn Sie auf diese Option klicken, sehen Sie den Marktplatz, auf dem Sie den gewünschten Dienst durch Sucheingabe finden können. Nachdem Sie „Azure-Suchressource“ ausgewählt haben, sehen Sie ein Formular mit den nächsten Feldern:
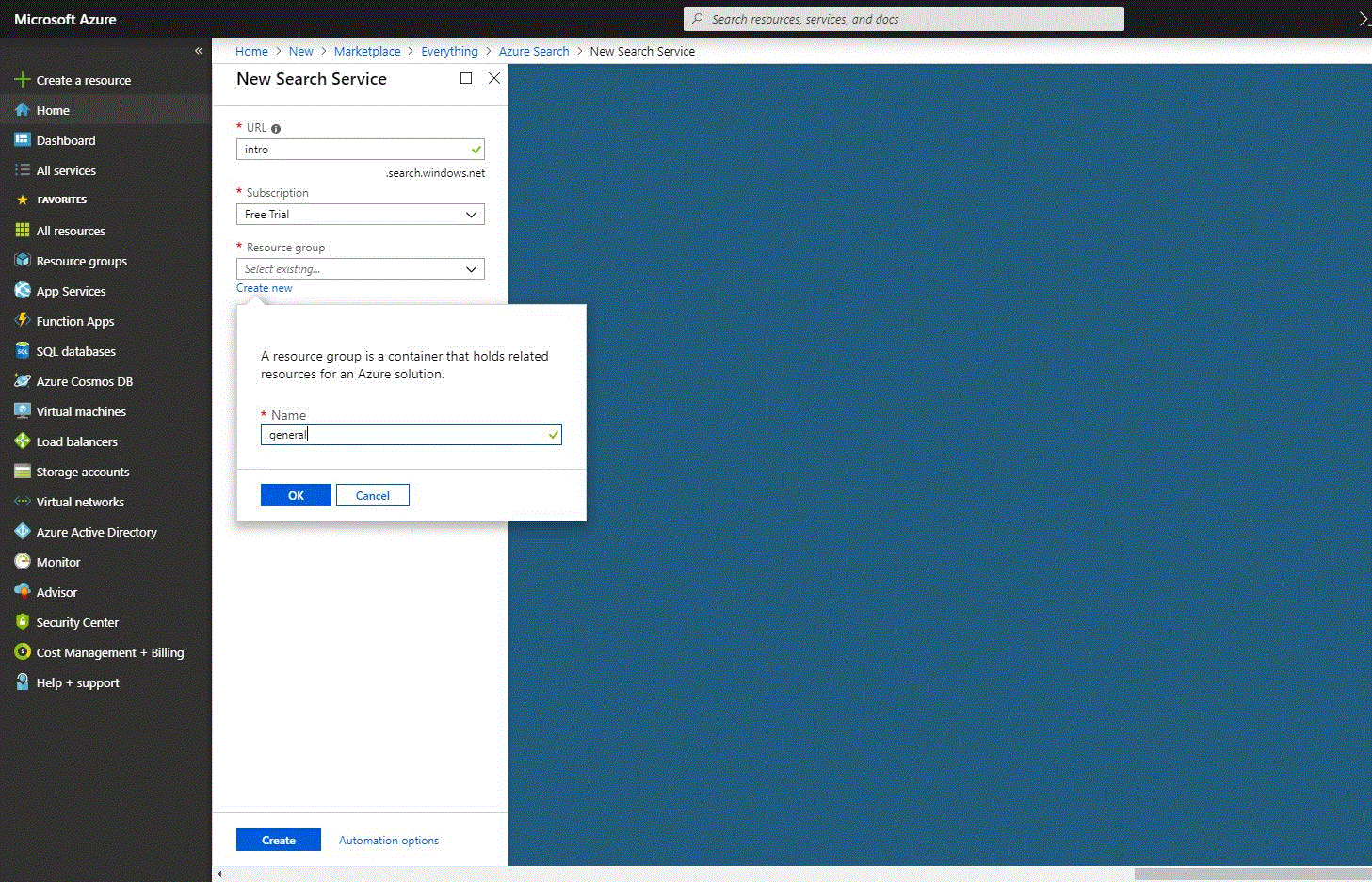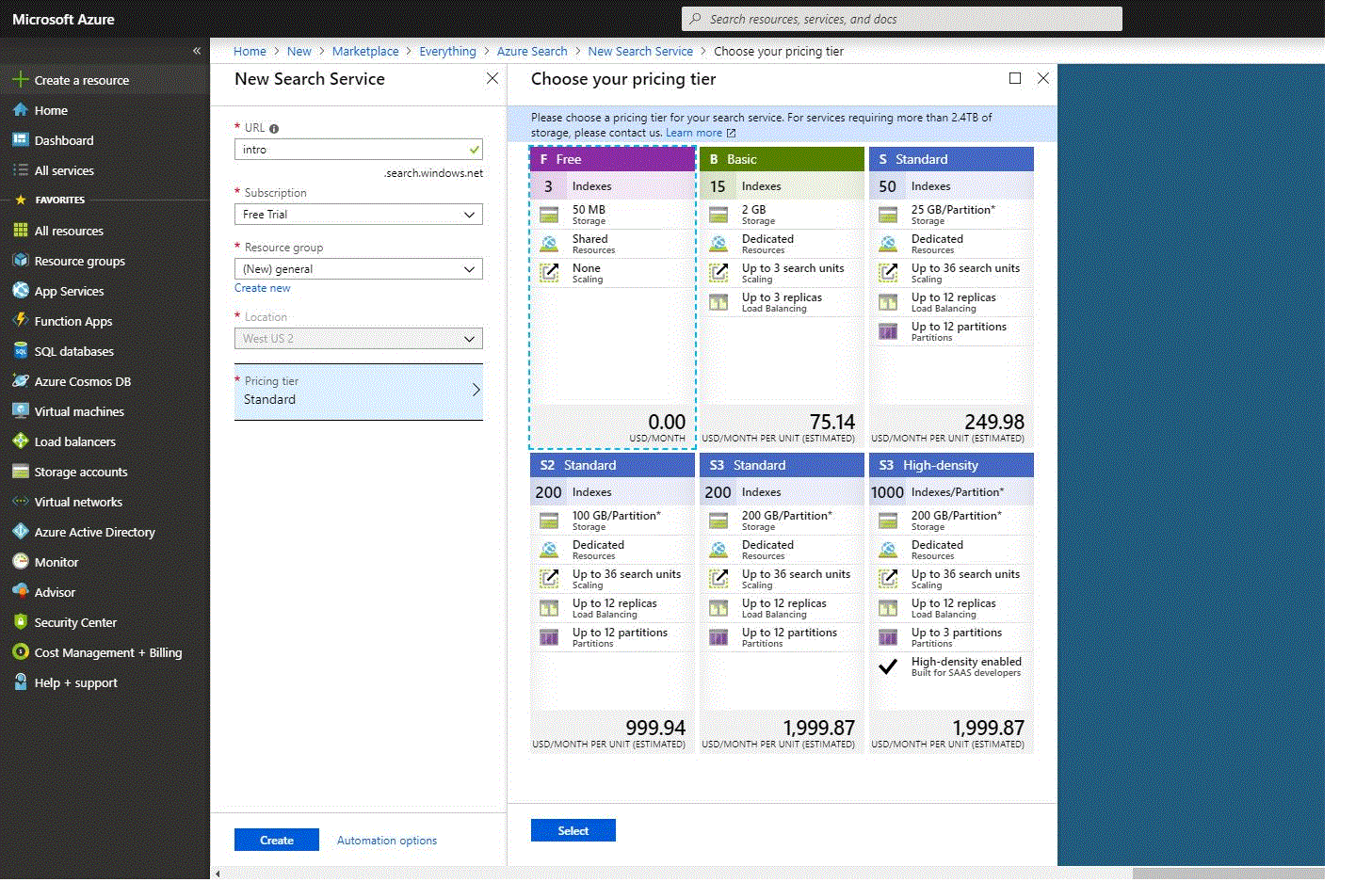
- URL – Sie müssen einen Dienstnamen angeben, der auch ein Teil des URL-Endpunkts ist, gegen den API-Aufrufe ausgegeben werden. Zum Beispiel wird unser Test-Endpunkt https://intro.search.windows.net sein, also wurde in das URL-Feld „intro“ eingegeben.
- Abonnement – wählen Sie das gewünschte Abonnement (Sie können mehrere haben). Wenn Sie ein kostenloses Testkonto erstellen, sehen Sie „Free Trial“-Abonnement ausgewählt. Azure Search kann Azure Table und Blob Storage, SQL Database und Azure Cosmos DB für die Indizierung automatisch erkennen, aber nur für die Dienste innerhalb desselben Abonnements.
- Eine Ressourcengruppe ist eine Sammlung von Azure-Diensten und -Ressourcen, die gemeinsam genutzt werden. Wenn Sie z. B. Azure Search zur Indizierung einer SQL-Datenbank verwenden, gehören beide Dienste zur gleichen Ressourcengruppe. Wenn Sie gerade ein Konto erstellt haben, können Sie auf die Schaltfläche „Neu erstellen“ unterhalb des Feldes klicken und die Ressourcengruppe durch Eingabe eines Namens erstellen.
- Der Standort ist der Ort, an dem ein Azure-Dienst gehostet werden soll. Wenn Sie die kognitive Suche nutzen möchten, müssen Sie eine Region wählen, in der die Funktion verfügbar ist.
- Preisstaffel – derzeit werden die Preisstaffeln Free, Basic und Standard angeboten. Jede von ihnen hat ihre eigenen Kapazitäten und Grenzen. Für dieses Beispiel wählen wir die Preisstufe „Free“, die auf drei Indizes, drei Datenquellen und drei Indexer beschränkt ist. Für künftige Anforderungen müssen Sie bedenken, dass eine Preisstufe nicht mehr geändert werden kann, sobald der Dienst eingerichtet ist. Wenn Sie später eine höhere oder niedrigere Stufe benötigen, müssen Sie den Dienst neu erstellen. Weitere Informationen finden Sie in der Anleitung “Wählen Sie eine Preisstufe oder SKU für Azure Search” auf einer offiziellen Website.
Auf den Screenshots unten ist ein kurzer Erstellungsprozess dargestellt:
Nachdem Sie auf die Schaltfläche „Erstellen“ geklickt haben, wird die erstellte Ressource angezeigt. Klicken Sie darauf, um detaillierte Informationen zu erhalten, wie unten dargestellt:
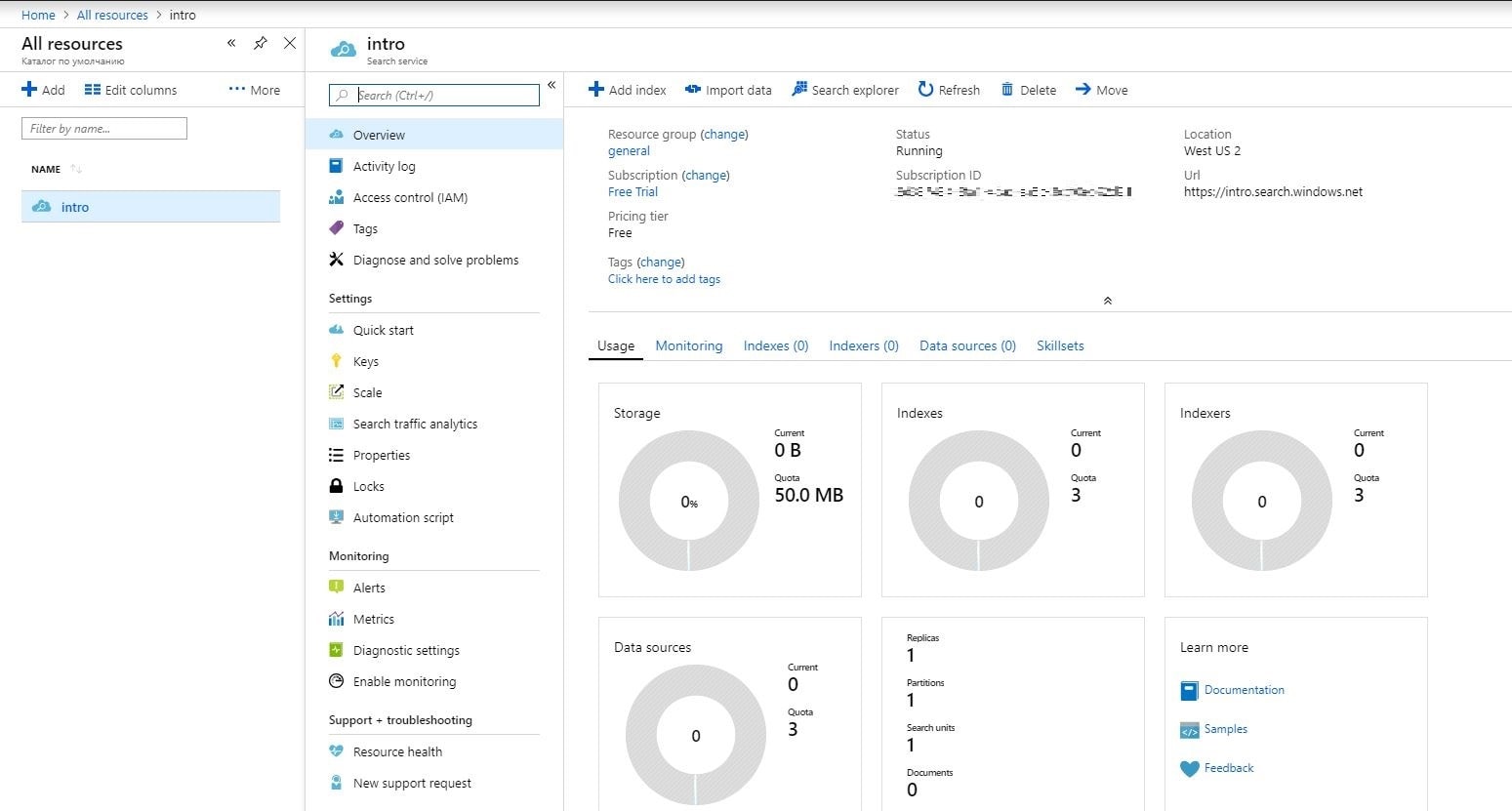
Auf der Dienstübersichtsseite finden Sie den URL-Endpunkt, Nutzungsinformationen, Aktivitätsprotokolle, Schlüssel und viele andere nützliche Informationen. Sie benötigen auch Ihre Schlüssel, die Sie durch Klicken auf den Abschnitt „Schlüssel“ im Navigationsbereich finden. Bei der Erstellung unseres Testprojekts müssen Sie einen der Admin-Schlüssel kopieren (sie sind gleichwertig), da dieser zum Erstellen, Aktualisieren und Löschen von Objekten im Dienst erforderlich ist.
Lassen Sie uns also das Projekt erstellen und mit der Erkundung der Azure Search-Funktionalität beginnen. Wir werden nach und nach neue Funktionen hinzufügen, um alle Schritte konsequent durchzugehen und ein möglichst umfassendes Verständnis der Vorgänge zu erreichen.
Projekt- und Indexerstellung
Die Azure Search-Funktionalität wird über eine REST-API oder ein .NET SDK bereitgestellt. In diesem Beispiel verwenden wir das Azure Search .NET SDK, das Anwendungen unterstützt, die auf das .NET Framework 4.5.2 und höher sowie auf .NET Core ausgerichtet sind. Sie können wählen, was Ihnen am besten passt, aber in diesem Beispiel werden wir ein .NET Core-Projekt erstellen:
- Öffnen Sie Visual Studio;
- Klicken Sie auf die Menüoption „Datei“ und wählen Sie dann die Optionen „Neu“ und „Projekt“;
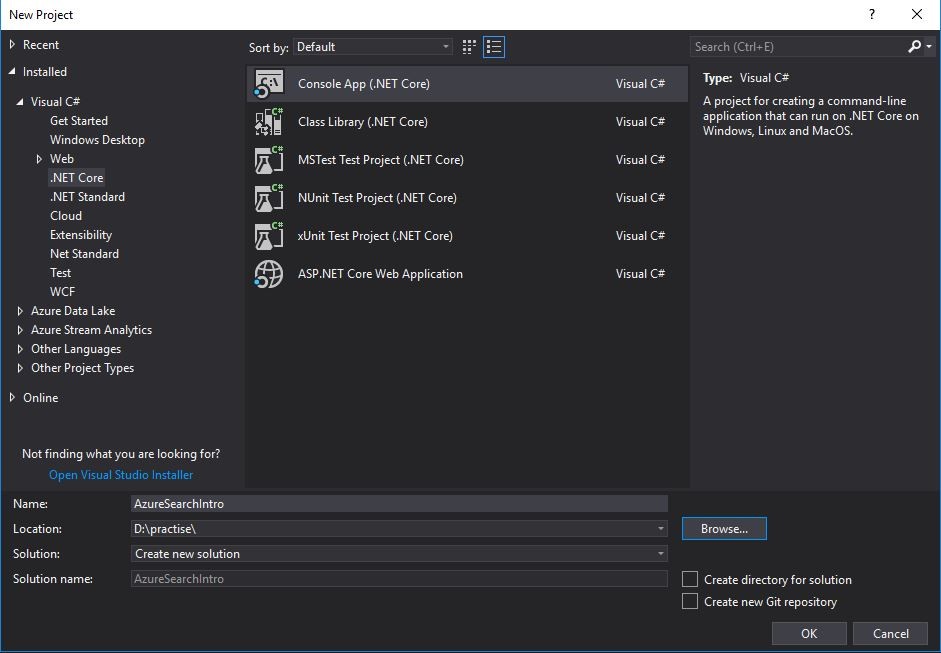
- Wählen Sie den Typ „Console App (.NET Core)“;
- Geben Sie Ihren Projektnamen und den Speicherort ein und klicken Sie auf „OK“.
Unser Projektname wird „AzureSearchIntro“ sein und hier ist der Screenshot des Schritts der Projekterstellung:
As we will use the .NET SDK, now, we need to download it through the NuGet package manager. For this, just right click on the project Da wir das .NET SDK verwenden werden, müssen wir es nun über den NuGet-Paketmanager herunterladen. Klicken Sie dazu mit der rechten Maustaste auf den Projektnamen, wählen Sie „NuGet-Pakete verwalten…“, wechseln Sie zur Registerkarte „Durchsuchen“ und suchen Sie nach dem Paket „Microsoft.Azure.Search“.
Wir werden auch eine Konfigurationsdatei hinzufügen, um alle Schlüssel an einem Ort zu speichern. Hierfür müssen Sie:
- Fügen Sie die folgenden NuGet-Pakete hinzu:
- Microsoft.Extensions.Configuration;
- Microsoft.Extensions.Configuration.FileExtensions;
- Microsoft.Extensions.Configuration.Json;
- Erstellen Sie eine JavaScript-JSON-Konfigurationsdatei: Klicken Sie mit der rechten Maustaste auf den Projektnamen, wählen Sie „Hinzufügen“ und dann die Option „Neues Element…“, wählen Sie den Typ „JavaScript-JSON-Konfigurationsdatei“ und benennen Sie sie (z. B. „appsettings.json“);
- Stellen Sie sicher, dass in der Datei appsettings.json die Eigenschaft „Copy to Output Directory“ auf „Copy if newer“ gesetzt ist, damit die Anwendung bei der Veröffentlichung darauf zugreifen kann.
Fügen Sie den Namen Ihres Dienstes und den API-Schlüssel ein, so dass die Konfigurationsdatei wie folgt aussieht:
{
"SearchServiceName": "intro",
"SearchServiceAPIKey": "[API key]"
}
Danach müssen wir ein Modell erstellen, das ein Dokument im Index darstellen wird. Fügen Sie eine neue Klasse hinzu (klicken Sie mit der rechten Maustaste auf den Projektnamen, wählen Sie „Hinzufügen“, dann die Option „Neues Element…“, wählen Sie den Typ „Klasse“ und nennen Sie sie „Restaurant“). Sie können jeden beliebigen Namen anstelle des im Beispiel gezeigten eingeben, denken Sie nur daran, wenn Sie den Code kopieren. Hier ist der Code dieser Datei, den Sie einfügen müssen:
using Microsoft.Azure.Search;
using Microsoft.Azure.Search.Models;
using Microsoft.Spatial;
using System.ComponentModel.DataAnnotations;
namespace AzureSearchIntro {
[SerializePropertyNamesAsCamelCase]
public class Restaurant {
[Key]
[IsFilterable]
public string RestaurantId { get; set; }
[IsSearchable, IsFilterable, IsSortable]
public string Name { get; set; }
[IsFilterable, IsSortable, IsFacetable]
public double? Rating { get; set; }
[IsFilterable, IsSortable]
public GeographyPoint Location { get; set; }
[IsFilterable, IsSortable, IsFacetable]
public int? WorkingHoursStart { get; set; }
[IsFilterable, IsSortable, IsFacetable]
public int? WorkingHoursEnd { get; set; }
[IsSearchable, IsFilterable, IsSortable]
public string PhoneNumber { get; set; }
}
}
Wie Sie sehen können, ist jede öffentliche Eigenschaft mit Attributen versehen, deren Definition im Folgenden beschrieben wird:
- IsSearchable kennzeichnet das Feld als im Volltext durchsuchbar. Das bedeutet auch, dass es bei der Indizierung einer Analyse wie der Worttrennung unterzogen wird, d. h. wenn Sie ein durchsuchbares Feld auf einen Wert wie „azure search“ setzen, wird es intern in zwei einzelne Token „azure“ und „search“ aufgeteilt.
- Mit IsFilterable kann das Feld in Filterabfragen referenziert werden. Dieses Attribut unterscheidet sich von IsSearchable durch die Behandlung von Zeichenketten. Filterbare Felder vom Typ Edm.String oder Collection(Edm.String) werden nicht durch Worttrennung getrennt, so dass Vergleiche nur für exakte Übereinstimmungen gelten. Wenn Sie z. B. den Wert eines solchen Feldes auf „azure search“ setzen und dann nach „azure“ filtern, werden keine Übereinstimmungen gefunden, aber wenn Sie nach „azure search“ filtern, werden Übereinstimmungen angezeigt.
- IsSortable gibt an, ob das Feld in OrderBy-Ausdrücken verwendet werden kann. Standardmäßig sortiert das System die Ergebnisse nach der Punktzahl, aber erfahrungsgemäß wollen die Benutzer nach den Feldern in den Dokumenten sortieren. Felder vom Typ Collection(Edm.String) können nicht sortierbar sein.
- IsFacetable wird typischerweise in einer Präsentation von Suchergebnissen verwendet, die die Trefferzahl nach Kategorie enthält. Diese Option kann nicht mit Feldern des Typs Edm.GeographyPoint verwendet werden.
Weitere Informationen über Attribute finden Sie in der offiziellen Dokumentation. Beachten Sie auch, dass die Länge der filterbaren, sortierbaren oder facettierbaren Edm.String-Felder nicht mehr als 32 Kilobyte betragen darf. Das liegt daran, dass solche Felder als ein einzelner Suchbegriff behandelt werden und die maximale Länge eines Begriffs in Azure Search 32 Kilobyte beträgt. Sie können mehr Text in einem einzelnen String-Feld speichern, wenn es vom Index ausgeschlossen ist. Das Feld gilt als ausgeschlossen, wenn es keine filterbaren, sortierbaren und Facetable-Attribute hat (oder diese in der REST-API explizit auf false gesetzt sind). Dies ist nützlich für Felder, die nicht in Abfragen verwendet werden, aber in Suchergebnissen benötigt werden. Der Ausschluss von Feldern aus dem Index verbessert auch die Leistung.
Das Attribut `SerializePropertyNamesAsCamelCase` weist das SDK an, die Eigenschaftsnamen automatisch in Camel-Case zu konvertieren. Es stellt sicher, dass Eigenschaftsnamen in der Modellklasse in Pascal-Schreibweise auf Feldnamen im Index in Camel-Schreibweise abgebildet werden.
Beim Entwerfen von Modellklassen, die auf einen Azure Search-Index abgebildet werden sollen, lautet die offizielle Empfehlung von Microsoft, Eigenschaften von Werttypen wie bool und int als nullable zu deklarieren. Wenn Sie keine nullable-Eigenschaft verwenden, müssen Sie garantieren, dass keine Dokumente in Ihrem Index einen Nullwert für das entsprechende Feld enthalten. Wenn Sie also ein neues Feld vom Typ Edm.Int32 zu einem bestehenden Index hinzufügen, werden nach der Aktualisierung der Indexdefinition alle Dokumente einen Nullwert für dieses neue Feld aufweisen. Wenn Sie dann eine Modellklasse mit einer nicht-nullbaren int-Eigenschaft für dieses Feld verwenden, erhalten Sie eine `JsonSerializationException` wenn Sie versuchen, Dokumente abzurufen.
Lassen Sie uns nun das Hauptprogramm mit dem folgenden Code aktualisieren:
using Microsoft.Azure.Search;
using Microsoft.Azure.Search.Models;
using Microsoft.Extensions.Configuration;
using System;
namespace AzureSearchIntro {
class Program {
static void Main(string[] args) {
var builder = new ConfigurationBuilder().AddJsonFile("appsettings.json");
IConfigurationRoot configuration = builder.Build();
string searchServiceName = configuration["SearchServiceName"];
string apiKey = configuration["SearchServiceAPIKey"];
SearchServiceClient serviceClient = new SearchServiceClient(searchServiceName, new SearchCredentials(apiKey));
if (!serviceClient.Indexes.Exists("restaurants")) {
var restaurantsIndex = new Index() {
Name = "restaurants",
Fields = FieldBuilder.BuildForType()
};
serviceClient.Indexes.Create(restaurantsIndex);
}
Console.WriteLine("{0}", "Complete. Press any key to end application...\n");
Console.ReadKey();
}
}
}
Wie Sie sehen können, werden zunächst der Name des Dienstes und der API-Schlüssel aus der Datei appsettings.json abgerufen und ein neues `SearchServiceClient`-Objekt erstellt, das die Verwaltung von Indizes ermöglicht. Als nächstes prüft Main, ob der Index mit dem Namen „restaurants“ existiert, und wenn nicht, wird er erstellt. Wenn Sie dieses Beispiel ausführen, werden Sie im Azure-Portal sehen, dass Sie jetzt 1 Index mit 0 Dokumenten und 0B Speichergröße haben.
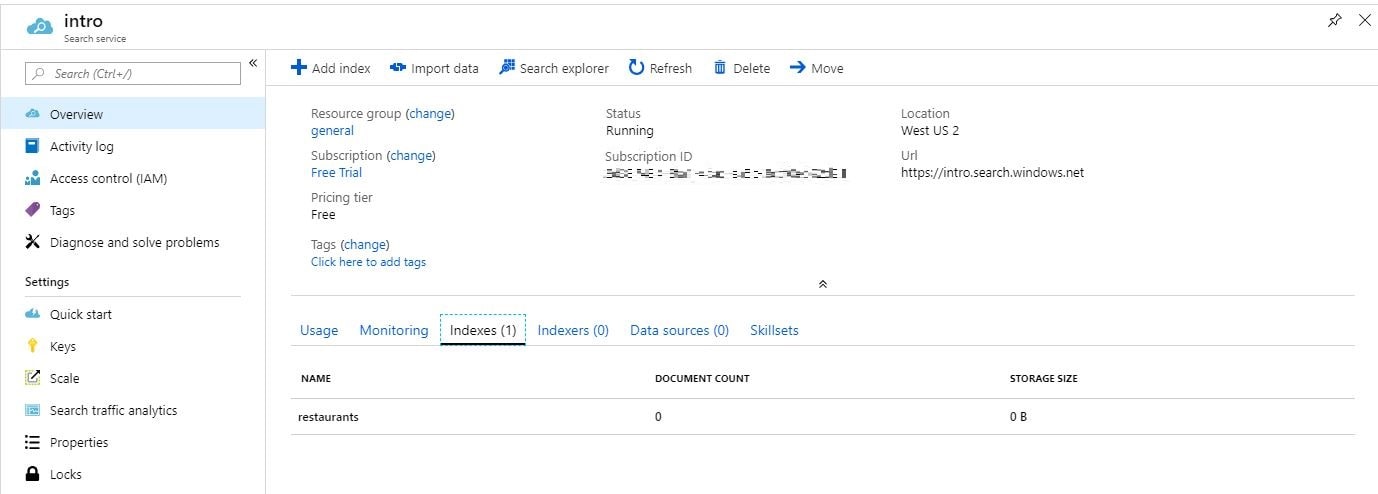
Index mit Dokumenten bestücken
Der nächste Schritt besteht darin, den Index mit Dokumenten aufzufüllen. Der folgende Code stellt die Datei „Program.cs“ dar und enthält den Code zum Auffüllen des Index mit Testdaten:
using Microsoft.Azure.Search;
using Microsoft.Azure.Search.Models;
using Microsoft.Extensions.Configuration;
using Microsoft.Spatial;
using System;
using System.Linq;
using System.Threading;
namespace AzureSearchIntro {
class Program {
static void Main(string[] args) {
var builder = new ConfigurationBuilder().AddJsonFile("appsettings.json");
IConfigurationRoot configuration = builder.Build();
string searchServiceName = configuration["SearchServiceName"];
string apiKey = configuration["SearchServiceAPIKey"];
SearchServiceClient serviceClient = new SearchServiceClient(searchServiceName, new SearchCredentials(apiKey));
if (!serviceClient.Indexes.Exists("restaurants")) {
var restaurantsIndex = new Index() {
Name = "restaurants",
Fields = FieldBuilder.BuildForType()
};
serviceClient.Indexes.Create(restaurantsIndex);
}
ISearchIndexClient indexClient = serviceClient.Indexes.GetClient("restaurants");
if (indexClient.Documents.Count() == 0)
UploadDataToIndex(indexClient);
Console.WriteLine("{0}", "Complete. Press any key to end application...\n");
Console.ReadKey();
}
public static void UploadDataToIndex(ISearchIndexClient indexClient) {
var restaurants = new Restaurant[] {
new Restaurant() {
RestaurantId = "1",
Name = "Best restaurant",
Rating = 2.7,
WorkingHoursStart = 8,
WorkingHoursEnd = 22,
PhoneNumber = "1-800-437-4370",
Location = GeographyPoint.Create(47.679512, -122.132441)
},
new Restaurant() {
RestaurantId = "2",
Name = "Italian food",
Rating = 4.8,
WorkingHoursStart = 10,
WorkingHoursEnd = 23,
PhoneNumber = "1-800-477-4777",
Location = GeographyPoint.Create(50.496163, 30.523571)
},
new Restaurant() {
RestaurantId = "3",
Name = "Chinese food",
Rating = 4.9,
WorkingHoursStart = 7,
WorkingHoursEnd = 23,
PhoneNumber = "1-800-480-4800",
Location = GeographyPoint.Create(50.447258, 30.526541)
}
};
var batch = IndexBatch.MergeOrUpload(restaurants);
try {
indexClient.Documents.Index(batch);
}
catch (IndexBatchException e) {
string failedDocuments = String.Join(", ", e.IndexingResults.Where(r => !r.Succeeded).Select(r => r.Key));
Console.WriteLine($"Failed to index next documents: {failedDocuments}");
}
Console.WriteLine("Indexing documents.\n");
Thread.Sleep(2000);
}
}
}
In `Main` wird geprüft, ob der Index Dokumente enthält oder nicht. Wenn nicht, wird mit der Methode `UploadDataToIndex` ein Array von Restaurant-Objekten erstellt, dann wird ein IndexBatch erstellt, der die Dokumente enthält, und die Operation angegeben, die auf den Batch angewendet werden muss. Der Stapel wird dann mit der `Documents.Index`-Methode in den Azure Search-Index hochgeladen. Bitte beachten Sie, dass alle Telefonnummern und Koordinaten fiktiv sind und nicht zu einem existierenden Ort gehören. In diesem Beispiel verwenden wir die Methode `MergeOrUpload`, um Dokumente hochzuladen, aber Sie können jede geeignete Methode aus der folgenden Liste verwenden:
- Hochladen wird das Dokument eingefügt, wenn es neu ist, und aktualisiert (ersetzt), wenn es bereits vorhanden ist. Beachten Sie, dass im Falle einer Aktualisierung alle Felder ersetzt werden.
- Zusammenführen aktualisiert ein bestehendes Dokument mit den angegebenen Feldern. Existiert das Dokument nicht, schlägt die Zusammenführung fehl. Jedes Feld, das Sie bei der Zusammenführung angeben, ersetzt das vorhandene Feld im Dokument.
- MergeOrUpload, wenn das Dokument mit dem angegebenen Schlüssel bereits im Index existiert, wird es ersetzt, andernfalls wird es hinzugefügt.
Eine weitere Besonderheit ist ein Catch-Block, der einen Indizierungsfehler behandelt. Der Azure Search-Dienst kann einige der Dokumente im Stapel nicht indizieren, wenn Ihr Dienst stark belastet ist. Die offizielle Empfehlung von Microsoft lautet, diesen Fall zu behandeln und die Indizierung fehlgeschlagener Dokumente zu wiederholen oder je nach Bedarf etwas anderes zu tun, z. B. zumindest in die Protokolldatei zu schreiben.
Suche nach Dokumenten
Der letzte und interessanteste Schritt ist die Suche nach Dokumenten im Index. Aktualisieren Sie die Datei „Program.cs“ mit dem folgenden Code:
using Microsoft.Azure.Search;
using Microsoft.Azure.Search.Models;
using Microsoft.Extensions.Configuration;
using Microsoft.Spatial;
using System;
using System.Collections.Generic;
using System.Linq;
using System.Threading;
using System.Threading.Tasks;
namespace AzureSearchIntro {
class Program {
static void Main(string[] args) {
var builder = new ConfigurationBuilder().AddJsonFile("appsettings.json");
IConfigurationRoot configuration = builder.Build();
string searchServiceName = configuration["SearchServiceName"];
string apiKey = configuration["SearchServiceAPIKey"];
SearchServiceClient serviceClient = new SearchServiceClient(searchServiceName, new SearchCredentials(apiKey));
if (!serviceClient.Indexes.Exists("restaurants")) {
var restaurantsIndex = new Index() {
Name = "restaurants",
Fields = FieldBuilder.BuildForType()
};
serviceClient.Indexes.Create(restaurantsIndex);
}
ISearchIndexClient indexClient = serviceClient.Indexes.GetClient("restaurants");
if (indexClient.Documents.Count() == 0)
UploadDataToIndex(indexClient);
Console.WriteLine("Searching...\n");
DocumentSearchResult results = SearchRestaurants(indexClient).GetAwaiter().GetResult();
Console.WriteLine($"Number of results: {results.Count}\n");
foreach (var item in results.Results) {
Console.WriteLine($"Score: {item.Score}");
Console.WriteLine($"Name: {item.Document.Name}");
Console.WriteLine($"Rating: {item.Document.Rating}");
Console.WriteLine($"WorkingHoursStart: {item.Document.WorkingHoursStart}");
Console.WriteLine($"WorkingHoursEnd: {item.Document.WorkingHoursEnd}");
Console.WriteLine($"PhoneNumber: {item.Document.PhoneNumber}");
Console.WriteLine("------------------------");
}
Console.WriteLine("Complete. Press any key to end application...\n");
Console.ReadKey();
}
public static void UploadDataToIndex(ISearchIndexClient indexClient) {
var restaurants = new Restaurant[] {
new Restaurant() {
RestaurantId = "1",
Name = "Best restaurant",
Rating = 2.7,
WorkingHoursStart = 8,
WorkingHoursEnd = 22,
PhoneNumber = "1-800-437-4370",
Location = GeographyPoint.Create(47.679512, -122.132441)
},
new Restaurant() {
RestaurantId = "2",
Name = "Italian food",
Rating = 4.8,
WorkingHoursStart = 10,
WorkingHoursEnd = 23,
PhoneNumber = "1-800-477-4777",
Location = GeographyPoint.Create(50.496163, 30.523571)
},
new Restaurant() {
RestaurantId = "3",
Name = "Chinese food",
Rating = 4.9,
WorkingHoursStart = 7,
WorkingHoursEnd = 23,
PhoneNumber = "1-800-480-4800",
Location = GeographyPoint.Create(50.447258, 30.526541)
}
};
var batch = IndexBatch.MergeOrUpload(restaurants);
try {
indexClient.Documents.Index(batch);
}
catch (IndexBatchException e) {
string failedDocuments = String.Join(", ", e.IndexingResults.Where(r => !r.Succeeded).Select(r => r.Key));
Console.WriteLine($"Failed to index next documents: {failedDocuments}");
}
Console.WriteLine("Indexing documents.\n");
Thread.Sleep(2000);
}
public static async Task<DocumentSearchResult> SearchRestaurants(ISearchIndexClient indexClient) {
List resultsList = new List();
var parameters = new SearchParameters();
parameters.Filter = "rating gt 4 and (geo.distance(location, geography'POINT(30.521541 50.444158)') le 30)";
parameters.OrderBy = new[] { "rating desc" };
parameters.QueryType = QueryType.Full;
parameters.SearchMode = SearchMode.All;
parameters.IncludeTotalResultCount = true;
parameters.Top = 10;
string azureSearch = $"(name:(('/.*food.*/'))) || (name:(('/.*Chinese.*/')))";
try {
var docResults = await indexClient.Documents.SearchAsync(azureSearch, parameters);
return docResults;
}
catch (Exception e) {
}
return null;
}
}
}
The following example will return the next search results after running:
Searching...
Number of results: 2
Score: 1.4142135
Name: Chinese food
Rating: 4.9
WorkingHoursStart: 7
WorkingHoursEnd: 23
PhoneNumber: 1-800-480-4800
------------------------
Score: 0.35355338
Name: Italian food
Rating: 4.8
WorkingHoursStart: 10
WorkingHoursEnd: 23
PhoneNumber: 1-800-477-4777
------------------------
Complete. Press any key to end application...
Schauen wir uns die Methode „SearchRestaurants“ im Detail an. Eine Abfrage akzeptiert mehrere Parameter, die Abfragekriterien liefern und auch das Suchverhalten festlegen:
-
- Filter ausdrücke schränken die Suche auf bestimmte Felder ein oder fügen Übereinstimmungskriterien hinzu. Sie können als eigenständige, vollständig ausgedrückte Abfrage ausgeführt werden oder eine Abfrage mit zusätzlichen Parametern verdeutlichen. Wir werden Filterausdrücke später unter der Übersicht der Suchparameter besprechen.
- Der Parameter OrderBy akzeptiert eine Liste von Sortierkriterien, wobei jedes Kriterium der Name eines sortierbaren Feldes, ein Aufruf der Funktionen geo.distance oder search.score sein kann. Sie können asc (Standardreihenfolge) oder desc verwenden, um die Sortierreihenfolge festzulegen. Die Reihenfolge der Ausdrücke bestimmt die endgültige Sortierreihenfolge.
- QueryType gibt an, welcher Parser verwendet werden soll. Es können zwei Typen verwendet werden:
- der standardmäßige einfache Abfrageparser, der für die Volltextsuche optimal ist (`QueryType.Simple`);
- der vollständige Lucene-Abfrageparser, der für erweiterte Abfragekonstrukte wie reguläre Ausdrücke, Proximity-Suche, Fuzzy- und Wildcard-Suche usw. verwendet wird (`QueryType.Full`).
- SearchMode gibt an, ob einer („SearchMode.Any“ Standardoption) oder alle („SearchMode.All“) der Suchbegriffe übereinstimmen müssen, um das Dokument als Treffer zu zählen.
- IncludeTotalResultCount gibt an, ob die Gesamtzahl der Ergebnisse in der Antwort benötigt wird oder nicht. Der Standardwert ist false.
- Top gibt an, wie viele Elemente zurückgegeben werden müssen. Kann auch mit dem Parameter „Skip“ für die Paginierung verwendet werden, der angibt, wie viele Elemente übersprungen werden müssen.
- SearchFields ist ein optionaler Parameter und wird verwendet, um die Suche auf bestimmte Felder zu beschränken. Sie können also die oben gezeigte Variable azureSearch durch die folgenden Codezeilen ersetzen:
parameters.SearchFields = new[] { "name" };
string azureSearch = $"('/.*food.*/') || ('/.*Chinese.*/')";
Der Filterparameter ist die Grundlage für verschiedene Sucherfahrungen, wie z. B. die Geolokationssuche, die facettierte Navigation, usw. Wie bereits weiter oben im Text erwähnt, gehen wir die Liste der Filteroperatoren durch, die verwendet werden können:
- logische Operatoren (`and`, `or`, `not`);
- Vergleichsausdrücke:
- `eq` – ist gleich;
- `ne` – nicht gleich;
- `gt` – größer als;
- `lt` – kleiner als;
- `ge` – größer als oder gleich;
- `le` – kleiner als oder gleich.
- CKonstanten der unterstützten Typen und Verweise auf Feldnamen (mit Attribut Filterable);
- `any` und `all`. Beide werden für Felder vom Typ `Collection(Edm.String)` unterstützt, können aber mit unterschiedlichen Ausdrücken verwendet werden:
- `any` kann nur mit einfachen Gleichheitsausdrücken oder mit einer `search.in` Funktion verwendet werden;
- `all` kann nur mit einfachen Ungleichheitsausdrücken oder mit einer `not search.in` verwendet werden.
- Geospatiale Funktionen `geo.distance` und `geo.intersects`, die für „find near me“ oder kartenbasierte Suchkontrollen verwendet werden;
- Die Funktion `search.in`, die prüft, ob ein gegebenes String-Feld gleich einem der Werte einer gegebenen Liste ist;
- Die Funktion `search.ismatch` wertet die Suchanfrage als Teil eines Filterausdrucks aus und gibt alle Dokumente zurück, die mit dieser Anfrage übereinstimmen;
- Die Funktion `search.ismatchscoring` ist der Funktion `search.ismatch` sehr ähnlich. Der einzige Unterschied besteht darin, dass die Relevanzbewertung der Dokumente, die mit der `search.ismatchscoring`-Abfrage übereinstimmen, sich auf die Gesamtbewertung des Dokuments auswirkt, während im Falle von `search.ismatch` die Bewertung des Dokuments nicht verändert wird.
Sie können mehr über die Feinheiten jedes der beschriebenen Parameter in der offiziellen Dokumentation nachlesen.
Der letzte, aber nicht minder interessante Punkt, den wir gleich besprechen werden, ist das Term Boosting. Es stuft ein Dokument höher ein, wenn es den verstärkten Begriff enthält, als Dokumente, die den Begriff nicht enthalten. Es unterscheidet sich von Scoring-Profilen dadurch, dass Scoring-Profile bestimmte Felder verstärken, nicht aber bestimmte Begriffe. Um einen Begriff zu verstärken, müssen Sie das Symbol „^“ mit einem Verstärkungsfaktor (eine Zahl) am Ende des gesuchten Begriffs verwenden. Je höher der Boost-Faktor ist, desto relevanter wird der Begriff im Vergleich zu anderen Suchbegriffen sein. Der Standardwert für den Verstärkungsfaktor ist 1, er kann kleiner als 1 sein, darf aber niemals negativ sein. Das folgende Beispiel veranschaulicht die Verwendung von Term Boosting. Aktualisieren Sie die Methode `SearchRestaurants` mit dem folgenden Code:
public static async Task<DocumentSearchResult> SearchRestaurants(ISearchIndexClient indexClient) {
List resultsList = new List();
var parameters = new SearchParameters();
parameters.Filter = "rating gt 1";
parameters.QueryType = QueryType.Full;
parameters.SearchMode = SearchMode.All;
parameters.IncludeTotalResultCount = true;
parameters.Top = 10;
string azureSearch = $"(name:food^2) || (name:restaurant)";
try {
var docResults = await indexClient.Documents.SearchAsync(azureSearch, parameters);
return docResults;
}
catch (Exception e) {
}
return null;
}
Nach der Ausführung erhalten Sie die folgenden Ergebnisse:
Searching...
Number of results: 3
Score: 0.30778623
Name: Italian food
Rating: 4.8
WorkingHoursStart: 10
WorkingHoursEnd: 23
PhoneNumber: 1-800-477-4777
------------------------
Score: 0.30778623
Name: Chinese food
Rating: 4.9
WorkingHoursStart: 7
WorkingHoursEnd: 23
PhoneNumber: 1-800-480-4800
------------------------
Score: 0.07599751
Name: Best restaurant
Rating: 2.7
WorkingHoursStart: 8
WorkingHoursEnd: 22
PhoneNumber: 1-800-437-4370
------------------------
Complete. Press any key to end application...
Wie Sie sehen können, stehen die Dokumente, die den verstärkten Begriff „food“ enthalten, an erster Stelle der Ergebnisse. Wenn Sie den Begriff „boost“ entfernen, sieht die Variable „azureSearch“ wie folgt aus:
string azureSearch = $"(name:food) || (name:restaurant)";
Sie werden andere Ergebnisse sehen, bei denen alle drei Dokumente in einer anderen Reihenfolge angeordnet sind:
Searching...
Number of results: 3
Score: 0.35786763
Name: Best restaurant
Rating: 2.7
WorkingHoursStart: 8
WorkingHoursEnd: 22
PhoneNumber: 1-800-437-4370
------------------------
Score: 0.18116833
Name: Italian food
Rating: 4.8
WorkingHoursStart: 10
WorkingHoursEnd: 23
PhoneNumber: 1-800-477-4777
------------------------
Score: 0.18116833
Name: Chinese food
Rating: 4.9
WorkingHoursStart: 7
WorkingHoursEnd: 23
PhoneNumber: 1-800-480-4800
------------------------
Complete. Press any key to end application...
Term Boost kann nützlich sein, wenn Sie eine Suche implementieren möchten, bei der der Nutzer einige einzelne Wörter eingeben kann und die Reihenfolge dieser Wörter die Relevanz jedes Wortes anzeigt. Wenn der Nutzer zum Beispiel auf der Kinoseite „Horror, Thriller, Drama“ in das Suchfeld eingibt, erscheinen bei der Begriffsanreicherung an der Spitze der Ergebnisse Horrorfilme, dann Thriller und dann Dramen.
Und das ist nicht einmal die Hälfte…
In diesem Artikel haben wir einige der häufigsten Anwendungsfälle von Azure Search in der Praxis besprochen. Die angebotene Funktionalität ist viel breiter und wir hoffen, dass Sie beim Lesen die grundlegenden Prinzipien der Nutzung verstanden haben und für weitere Studien inspiriert wurden.
Über Redwerk
Unser Unternehmen ist spezialisiert auf kundenspezifische Softwareentwicklung für Branchen wie E-Commerce, Business Automation, E-Health, Media & Entertainment, E-Government, Game Development, Startups & Innovation. Eine der Technologien, die wir verwenden und den Unternehmen zur Verfügung stellen, ist die Azure-Anwendungsentwicklung. Unser engagiertes Entwicklungsteam hat bereits Dutzende von erfolgreichen Lösungen mit Azure-Technologie geliefert. Entdecken Sie mit uns die Macht der SaaS-Plattformen.
